为什么要进行因子正交化处理?
由ypyu创建,最终由ypyu 被浏览 90 用户
摘要
选股多因子模型中常进行因子正交化处理。如果因子之间不满足正交性,则它们会相互影响各自的回归系数,这可能造成回归系数过大的估计误差,对因子的评价产生负面影响。
多因子模型求解
在选股多因子模型中,人们常提到的一个概念是因子正交化处理。本文就从多因子截面回归求解的角度来简单说说为什么我们喜欢相互正交的因子,以及如果因子之间不正交对回归系数会有什么影响。
一个多因子模型可以写成如下的形式:
y=Xb+ε
其中 y 是 N×1 阶股票下一期的收益率向量, X 为 N×K 阶当期的因子暴露矩阵, b 为 K×1 阶待通过回归求解得到的因子收益率向量, ε 为 N×1 阶残差向量。假设 X 满足列满秩,则上述模型的 OLS(ordinary least squares)回归求解为:
b=(XTX)−1XTy
需要注意的是,在上面这个模型以及 b 的表达式中,因子向量 X 已经包括了所有的 regressors,因此回归模型右侧没有额外的截距项。这意味着,如果我们假设截距项也是一个因子,则它对应的 N×1 阶向量 [1,1,…,1]T 已经作为 X 的某一列(通常是第一列)存在于 X 之中了;如果我们假设截距项不是一个因子,则 X 中没有 [1,1,…,1]T 这一列。
在 Barra 的多因子模型 CNE5 中考虑了国家因子,所有个股在该因子上的暴露都是 1,因此它的作用就相当于一个截距因子; [1,1,…,1]T 这个向量在 Barra 模型中正是 X 的第一列。另外,对于我们最熟悉的 simple regression model,它的右侧只有一个截距和一个解释变量:
yi=a+bxi+εi
按照上述说明,该模型对应的矩阵 X 包括两列:一列对应截距,一列对应真正的解释变量 x :
X=[1x11x2⋮⋮1xN]
从 b 的表达式来看,它和 XTX 有关。当 X 的各列(即回归模型中的不同解释变量,或我们研究问题中的不同因子暴露向量)之间不正交时,则在计算 XTX 乃至最终的 b 时, X 不同列之间是相互影响的,而这种影响不是什么好事儿。
简单一元回归
让我们从最简单的一元回归(simple univariate regression)说起。
假设有一元回归模型 y=bx+ε (模型右侧只有一个解释变量,没有截距项)。对于两个同阶向量 m 和 n ,令 ⟨m,n⟩ 表示它们的內积,即 ⟨m,n⟩=∑mini ,则该一元回归模型的 OLS 解为(求解对象就是标量 b ):
b=⟨x,y⟩⟨x,x⟩
这个结论非常简单,但是它十分重要。在上一节中,我们给出了多元回归 OLS 求解的表达式:
b=(XTX)−1XTy
比较一元回归模型的标量 b 和多元回归模型的向量 b 不难发现如下现象:在多元回归模型中,如果所有的解释变量两两正交,即 ⟨xi,xj⟩=0,i≠j ,则向量 b 中的每一个系数 bi 恰恰等于:
bi=⟨xi,y⟩⟨xi,xi⟩
这是因为 ⟨xi,xj⟩=0 保证了 XTX 的所有非对角元素都是 0,因此它是一个对角阵。对角阵的逆矩阵就是把该对角阵对角线上的元素都取倒数,所以逆矩阵仍然是对角阵。因此, XTX 的第 i 个对角元素为 1/⟨xi,xi⟩ 。另一方面, XTy 是一个 K×1 向量,它的第 i 个元素是 xi y 和 y 的內积,即 ⟨xi,y⟩ 。最终,多元回归的 bi 正是 ⟨xi,y⟩/⟨xi,xi⟩ 。
怎么样? bi 和一元回归中的 b 的表达式一模一样,说明当所有解释变量相互正交时,不同的因子(即 xi )对彼此的参数估计(即 bi **,因子收益率)没有任何影响。**这便是正交的好处。
那么,当因子(解释变量)之间不正交时又会怎样呢?为了回答这个问题,我们首先来看看回归的几何意义。
回归的几何意义
将 b 的表达式代入回归模型得到 ε 的表达式,并计算 X 和 ε 的內积有;
XTε=XT(y−Xb)=XT(y−X(XTX)−1XTy)=XTy−(XTX)(XTX)−1XTy=XTy−XTy=0
上式说明,OLS 的残差 ε 和解释变量 X 正交。来看看这在几何上意味着什么。
首先考虑最简单的情况,即一元回归 y=bx+ε (再次提醒,没有截距项)。它的几何意义如下图所示:
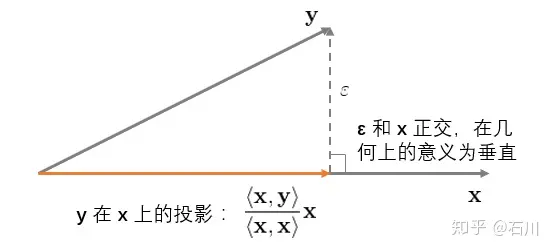
这个图说明,OLS 回归实际上将 y 垂直投影到(orthogonally projected onto) x 之上,使得 y 和其在 x 上的投影之间的距离( ε 的长度)最短(残差平方和最小)。这就是 OLS 的几何意义。
再来看看二元回归 y=b1x1+b2x2+ε ,并首先假设 x1 和 x2 之间是正交的。该回归的几何意义如下:
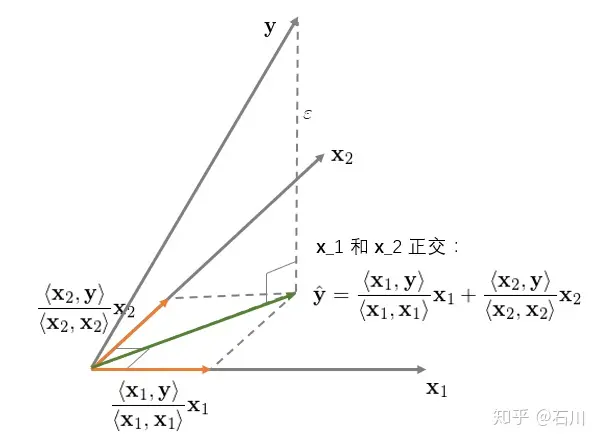
对于二元回归,它的几何意义是将 y 垂直投影到由 x1 和 x2 生成的超平面内,其投影正如上图中绿色向量所示。此外,我们可以分别、独立的将 y 投影到 x1 和 x2 上(图中两个橘黄色向量)。在本例中,由于 x1 和 x2 **相互正交(垂直),因此绿色向量恰好等于两个橘黄色向量之和。**这说明当 x1 和 x2 正交时,回归系数 bi 仅由 x1 和 y 决定、其他任何解释变量 xj(j≠i) 对 bi 均没有影响。
下面来看看 x1 和 x2 非正交的情况。该二元回归的几何意义如下:
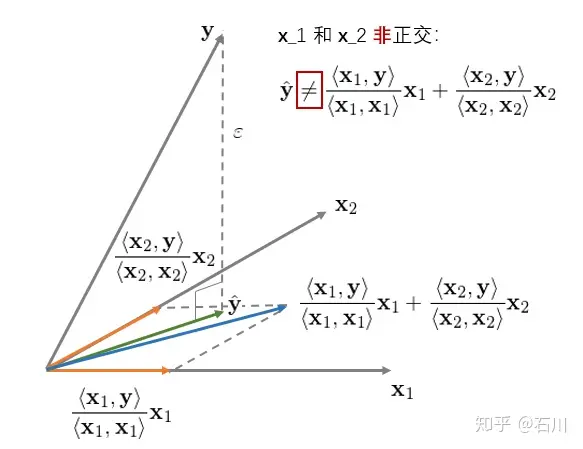
它和前一种情况最大的区别是,当 x1 和 x2 非正交时, y 在由 x1 和 x2 生成的超平面内的投影不等于 y 分别在 x1 和 x2 **上的投影之和。**在这种情况下,解释变量之间对各自的回归系数有不同的作用,因此 OLS 的回归系数 bi 不再等于 ⟨xi,y⟩/⟨xi,xi⟩ 。
非正交 xi 之间的相互作用如何影响回归系数 bi 呢?通过连续正交化来求解多元线性回归可以回答这个问题。
用正交化过程求解多元回归
还是拿我们最熟悉的 simple regression model 为例;该模型有两个解释变量 —— 截距项和 x 。
yi=a+bxi+εi
令 x0 表示截距项对应的解释变量,即 x0=[1,1,…,1]T ; x1 表示上式中的解释变量 x 。假设 x0 和 x1 非正交(正交的话我们就不用费劲了)。对于简单回归模型,回归系数 a (对应 x0 )和 b (对应 x1 )的解为:
b=∑xiyi−1n∑xi∑yi∑xi2−1n(∑xi)2a=1n∑yi−b(1n∑xi)
下面就来看看如何通过正交化求解 a 和 b 。由于 x0 和 x1 非正交,首先需要构造出一组正交向量。令 z0=x0 为其中的一个向量,将 x1 用 z0 进行一元回归(不带截距)得到的残差就是和 z0 互相垂直(正交)的向量,记为 z1 。由一元回归的性质可知:
z1=x1−⟨z0,x1⟩⟨z0,z0⟩z0=x1−x¯1
其中 x¯ 表示 x 的均值, 1 表示列向量 [1,1,…,1]T ,即 z0 。
So far so good?接下来,注意了:
将 y 用上面得到的 z1 进行一元回归(不带截距),得到的回归系数就是上述 simple regression model 中解释变量 x 的回归系数 b !
b=⟨z1,y⟩⟨z1,z1⟩=⟨x1−x¯1,y⟩⟨x1−x¯1,x1−x¯1⟩=∑xiyi−x¯∑yi∑(xi−x¯)2=∑xiyi−1n∑xi∑yi∑(xi2−2xix¯+x¯2)=∑xiyi−1n∑xi∑yi∑xi2−2(∑xi)x¯+nx¯2=∑xiyi−1n∑xi∑yi∑xi2−2nx¯2+nx¯2=∑xiyi−1n∑xi∑yi∑xi2−nx¯2=∑xiyi−1n∑xi∑yi∑xi2−1n(∑xi)2
怎么样?我们并没有直接对该模型求解,而是通过正交化的方式就求出了解释变量 x1 的回归系数 b 。反应快的小伙伴也许马上会问 a 呢? a 是否等于 ⟨z0,y⟩/⟨z0,z0⟩ 呢?别急,我们一会儿就聊 a ,但是在那之前先来看一个通过连续正交化求解多元回归的算法(Hastie et al. 2016):

该算法的核心是通过连续的正交化计算把一组非两两正交的向量 xi 转换成一组两两正交的向量 zi **,并以此方便的求出最后一个被正交化的解释变量的多元回归系数。**虽然它只有三步,但是每一步都值得解读一下:
1. 第一步是初始化,在所有解释变量中(如果回归中有截距项,就把 [1,1,…,1]T 看做一个解释变量)任意挑选一个当作 x0 进行初始化 z0=x0 。
2. 第二步是根据我们自己选定的递归顺序(任意顺序都可以),对 x1,x2,⋯,xp 依次进行正交化。例如,对 xj 的正交化处理就是用它和之前已经被处理过后的正交向量 z0,z1,⋯,zj−1 逐一独立一元回归得到系数 ⟨zk,xj⟩/⟨zk,zk⟩,k=0,1,⋯,j−1 ,进而用 xj 减去 (⟨zk,xj⟩/⟨zk,zk⟩)zk,k=0,1,⋯,j−1 之和,得到的残差就是最新的正交化后的向量 zj 。
3. 使用 y 和 zp 进行一元回归,得到的系数 ⟨zp,y⟩/⟨zp,zp⟩ 正是这个多元回归 OLS 求解中原始解释变量 xp 的回归系数 bp 。注意,这一结论仅对最后一个(第 p 个)被正交化后的解释变量成立。换句话说,对于别的解释变量 j<p , ⟨zj,y⟩/⟨zj,zj⟩ 并不是多元回归中原解释变量 xj 的回归系数。
看到这里,有的小伙伴可能会问,这个算法确实不错,但是费了半天劲算出了一大堆相互正交的向量 zj ,但是求解回归系数的结论仅对最后一个被正交化的解释变量成立,这不是坑爹吗?
答案是并不坑爹!这是因为上述算法中的关键一点是,正交化这些解释变量的顺序是任意的。我们可以选任何一个来初始化,也可以选任何一个作为最后一个被正交化的解释变量。无论我们怎么选,上述过程都保证了最后一个被正交化的解释变量的回归系数满足 bp=⟨zp,y⟩/⟨zp,zp⟩ 。因此,**我们只需要依次挑选这些解释变量作为最后一个被正交化的,就可以通过上述步骤方便的求出它们的回归系数。**而它所反映出来的本质是:
在多元线性回归中,解释变量 xj 的回归系数 bj 等于 xj 在被其他 x0,x1,⋯,xj−1,xj+1,⋯,xp 调整之后(即正交化,从而排除其他 xi 对 xj 的影响)仍能够对 y 产生的增量贡献。
这个算法叫作多元回归的 Gram-Schmidt(格拉姆-施密特)正交化过程。
本小节开始的 simple regression model 已经验证了上述结论。我们使用 x0 将 x1 正交化处理得到 z1 ,然后用 y 和 z1 回归得到的正是 x1 的回归系数 b ;如果将 x1 选为 z0 ,然后用它正交化 x0=[1,1,…,1]T ,就可以方便的求出回归系数 a 。
让我们来好好审视一下这个结论,即:
bp=⟨zp,y⟩⟨zp,zp⟩
上式说明,解释变量 xp 的回归系数 bp 和正交化后的 zp 的大小( zp 自己的內积为分母)有关。如果 xp 和其他解释变量高度相关(即非常不正交),那么 zp 就会很小,则会导致 bp 非常不稳定(一点点样本数据的变化都会导致 bp **的大幅变化)。**当 yi 满足独立同分布时,假设它的方差为 σ2 ,可以证明回归系数 bp 的方差和 zp 的大小成反比,即 ‖zp‖2 越小, bp 的误差越大:
var(bp)=σ2⟨zp,zp⟩=σ2‖zp‖2
在多因子模型中, bp 代表的是因子 p 的收益率。**为避免因子收益率的估计非常不稳定,要求不同的因子之间尽量满足正交化。**举例来说,在 Barra 的 CNE5 模型中,非线性规模因子和规模因子之间进行了正交化处理;残差波动率因子和规模以及 BETA 因子也进行了正交化处理。
在结束本小节的讨论之前,我还想介绍一个有意思也有用的特性。本节的论述说明我们可以任选一个解释变量作为最后一个,然后根据连续正交化方便的求出它的回归系数。这意味着如果我们有 20个解释变量,需要进行 20 次上述操作。那么,是否存在什么办法仅通过进行一次连续正交化就求出所有的回归系数 bj,j=0,1,⋯,p 呢?答案是肯定的。
假设我们按照某给定顺序 x0,x1,⋯,xp 进行了连续正交化过程,得到了 z0,z1,⋯,zp ,且我们现在知道 bp=⟨zp,y⟩/⟨zp,zp⟩ 。由于 bp 正是解释变量 xp 的回归系数,因此 bpxp 正是 xp 所解释的 y 的部分。如果从 y 中剔除 bpxp ,并把得到的 y−bpxp 用 x0,x1,⋯,xp−1 回归,则结果就和 xp 无关了。在这个新的回归中, xp−1 就变成了最后一个被正交化的解释变量,其对应的正交向量为 zp−1 。因此, xp−1 的回归系数就是用新的 y−bpxp 和 zp−1 回归的结果:
bp−1=⟨zp−1,y−bpxp⟩⟨zp−1,zp−1⟩
以此类推,我们可以按照 bp,bp−1,⋯,b0 的倒序求解出多元回归中所有解释变量的回归系数 bj (Drygas 2011):
bp=⟨zp,y⟩⟨zp,zp⟩bj=⟨zj,y−∑i=j+1pbixi⟩⟨zj,zj⟩, j=p−1,p−2,⋯,0
最后用本小节开始的 simple regression model 检验一下。我们用上述方法求解截距项的回归系数 a 看看。根据定义有 z0=1 并假设已知 b 。则根据上面的表达式可得:
a=⟨1,y−bx⟩⟨1,1⟩=∑yi−b∑xin=1n∑yi−b(1n∑xi)
这正是直接求解 simple regression model 得到的回归系数 a (请往前滚屏比较看看)。
一个例子
本节用一个例子来验证一下上一节的各种公式。假设有四个解释变量 x0 到 x3 ,以及 y :
x0=[11111111],x1=[12437635],x2=[01289462],x3=[13325804],y=[31415926]
直接使用回归系数 b 的表达式求解,则它们的回归系数分别为:b0=0.38548073, b1=0.96332683, b2=−0.36300685, b3=0.37189391。按照 x0,x1,x2,x3 的顺序进行连续正交化,得到的正交向量为:
z0=x0z1=x1−⟨x1,z0⟩⟨z0,z0⟩z0z2=x2−⟨x2,z0⟩⟨z0,z0⟩z0−⟨x2,z1⟩⟨z1,z1⟩z1z3=x3−⟨x3,z0⟩⟨z0,z0⟩z0−⟨x3,z1⟩⟨z1,z1⟩z1−⟨x3,z2⟩⟨z2,z2⟩z2
z0=[11111111],z1=[−2.875−1.8750.125−0.8753.1252.125−0.8751.125],z2=[−1.51082251−1.37662338−2.108225114.757575762.29437229−1.839826842.75757576−2.97402597],z3=[−0.008449841.08972192−1.026117681.06099247−0.482869872.17022584−1.56337379−1.24012905]
使用 Drygas (2011) 提出的解法按照 b3,b2,b1,b0 的顺序求解各个回归系数 bj :
b3=⟨z3,y⟩⟨z3,z3⟩b2=⟨z2,y−b3x3⟩⟨z2,z2⟩b1=⟨z1,y−b3x3−b2x2⟩⟨z1,z1⟩b0=⟨z0,y−b3x3−b2x2−b1x1⟩⟨z0,z0⟩
上述公式求出 b0=0.38548073, b1=0.96332683, b2=−0.36300685, b3=0.37189391,和使用回归系数 b 的表达式求解的结果完全一致。另外,我们也可以分别选择 x0,x1,x2 替换 x3 作为最后一个被正交化的解释变量(前三个变量的顺序也不重要),并利用 bp=⟨zp,y⟩/⟨zp,zp⟩ 求解,得出的 bj 也和上面的完全相同。
正交等于不相关?
在我们平常说因子之间正交的时候,另一个常用的词汇是因子之间“不相关”(这里不相关指的是不同因子的 Pearson 相关系数为零)。那么“正交”和“不相关”是否等价呢?
从定义出发,两个因子向量 x1 和 x2 正交意味着它们的內积,即 ⟨x1,x2⟩ 为零。而 x1 和 x2 的相关系数为零则意味着 ⟨x1−E[x1]⋅1,x2−E[x2]⋅1⟩ 为零,因为在计算相关系数时,必须先分别减去其均值,这就是个 centering 的过程。由于 ⟨x1,x2⟩ 为零不一定意味着 ⟨x1−E[x1]⋅1,x2−E[x2]⋅1⟩ 也为零,因此正交不一定等于不相关。
举个例子, [4,2]T 和 [3,−6]T 的內积为零,这两个向量正交。而各自减去均值后, [4,2]T 和 [3,−6]T 分别变为 [1,−1]T 和 [4.5,−4.5]T 。这两个新向量在一条直线上、內积不为零,因此 [4,2]T 和 [3,−6]T 的相关系数不为零(事实上,它们的相关系数等于 1)。从多元回归求解的角度来说,我们在乎的是他们是否正交,而非 centering 之后的內积是否为零(即是否不相关)。
不过对于因子暴露向量来说,因为个股在每个因子上的暴露都经过 demean 处理了,所以每个因子向量的均值已经是零了(这里考虑的就是简单等权均值的情况,而不是像 Barra 那种用市值作为权重进行去均值的情况)。从这个意义上说,因子向量之间正交和它们之间不相关等价。
结语
一不留神又写了这么长。从阅读体验来说,实在抱歉。
本文掰扯了一大堆公式其实就是想说明下面这句话:
在多元线性回归中,解释变量 xj的回归系数 bj等于 xj在被其他 x0,x1,⋯,xj−1,xj+1,⋯,xp调整之后(即正交化,从而排除其他 xi对 xj的影响)仍能够对 y 产生的增量贡献。如果 xj 和其他解释变量高度相关,则它的回归系数 bj 会有很大的估计误差。这对于多因子模型中评价因子收益非常不利。
如果看完之后你对这句话有一定的体会,那我的功夫就没白花。
在计算机算法进行多元回归求解的时候,并不是试图按照 b 的公式计算 XTX 的逆矩阵,而采用的正是正交化的思路。在正交化的过程中可以非常容易的得到 X 的 QR 分解,其中 Q 是正交阵、 R 是上三角阵。这也极大的化简了回归系数 b 以及 y 预测值的求解。由于篇幅原因(我也好意思说篇幅……),本文就不给出 QR 分解的具体表达式了,感兴趣的读者请参考 Hastie et al. (2016)。
参考文献
- Drygas, H. (2011). On the Relationship between the Method of Least Squares and Gram-Schmidt Orthogonalization. Acta et Commentationes Universitatis Tartuensis de Mathematica, Vol. 15(1), 3 – 13.
- Hastie, T., R. Tibshirani, and J. Friedman (2016). The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd Ed. Springer.
\