论文分享:Understanding Deep Learning Requires Rethinking Generalization
由iquant创建,最终由iquant 被浏览 18 用户
论文: Understanding Deep Learning Requires Rethinking Generalization
论文来自:ICRL2017 BEST PAPER AWARD
转载请注明出处:学习ML的皮皮虾 - 知乎专栏
深度人工神经网络通常拥有比训练样本数量更多的模型参数,然而一些模型却表现出更好的泛化能力(small generalization error,generalization error指的是train error和test error之间的差距),同时我们也很容易得到一些泛化能力比较弱的网络结构。这篇论文就是想要讨论为什么有的网络泛化能力比较好,而有的却不是很好。
针对这个问题,统计学习理论(statistical learning theory)已经有一些复杂度的度量方法(complexity measures),比如VC dimension、Rademacher complexity和uniform stability。而且当模型参数比较多的时候,理论上我们需要一些正则方法(regularization)来保证一个较小的泛化误差。
这篇论文觉得传统对于泛化能力的看法不能够解释不同神经网络之间泛化能力的本质区别。具体来说,是从以下几个方面的实验展开的:
- Randomization tests
- The role of explicit regularization
- Finite sample expressivity
- The role of implicit regularization
Randomization tests
这个部分的实验对训练数据进行污染,然后观察网络在污染的训练数据上的训练结果。按照不同的污染手段和污染程度,具体有这些实验:
- True label:无污染,原始数据
- 标签污染:
- Partially corrupted labels:对每个样本的真实标签以一定概率替换为一个随机类别标签
- Random labels:所有样本的真实标签都替换为随机的类别标签
- 样本污染:
- Shuffled pixels:随机选择一种像素顺序,以这个顺序重排所有训练和测试样本的像素
- Random pixels: 对每个样本各随机应用一种像素顺序
- Gaussian:对每一个样本,用和原样本一样均值和方差的高斯分布随机生成随机的图片


论文中说,对于不同污染的数据,用的是同样的训练超参进行的训练,实验结果如上图所示。实验结果简单来说就是,不管怎么对数据动手脚,网络都能把训练误差学到0(图a)。不过,随着数据污染的加重,网络的收敛速度变慢(图b),泛化能力也变差(图c)。
接着论文表示,之前对于泛化能力的理论并不能很好地解释现实情况。一方面是指的VC dimension、Rademacher complexity和uniform stability这些之前的工作。另一方面就是下一部分对于正则的实验结果。
(这里由于原文里没有具体说VC dimension、Rademacher complexity和uniform stability这些之前的工作不能解释实验结果的原因,我说一下我的理解,按照之前的理论,深层的神经网络复杂度是很高的,很容易过拟合,这和实验中拟合随机标签是符合的。但是没法解释一般情况下深层网络的泛化能力从何而来。)
The role of explicit regularization
一般我们认为在模型参数比较多的时候,加入正则是一种比较好的防止过拟合的方法。因为当模型比较复杂的时候,假设空间会变得巨大,而正则帮助我们对假设空间进行了“剪枝”。这篇论文使用了几种神经网络中比较常用的正则方法:
- 显式的正则:
- Data augmentation,Weight decay和Dropout。
- 隐式的正则:
- Early stop,Batch normalization
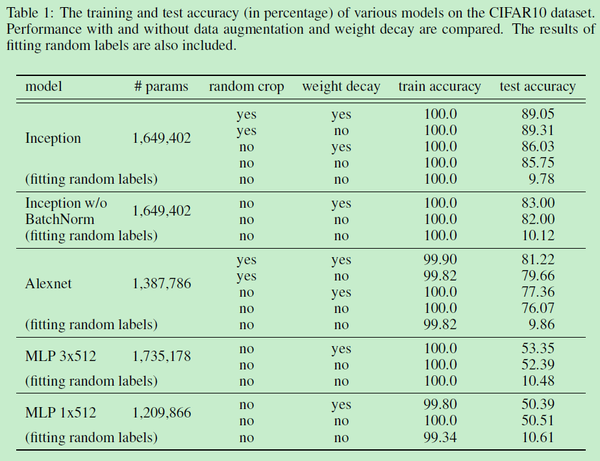





实验的结果比较多,但是结论比较简单,这篇论文觉得虽然这些正则方法确实能提高网络的泛化能力,但是正则方法并不是网络有较好泛化能力的关键,因为网络去掉这些正则方法,也能取得一个还不错的结果;同时,网络依靠正则化提高的泛化能力,可能还不如换另一种网络结构提高得多。
Finite sample expressivity
这篇论文认为之前大部分对于神经网络的表达能力的工作都太侧重于“population level”的结论。这篇论文认为与实践中更相关的应该是在有限样本情况下神经网络的表达能力。并得出了一个结论:


The role of implicit regularization
最后这篇论文以一个线性模型为例,讨论了SGD(stochastic gradient descent)本身带有隐含的正则化作用。


这篇论文从一个普通的经验风险最小开始, 为样本数量,假设
是一个
维的特征向量。(论文中说)当
时我们可以拟合任何标签,那么这样一个模型是否能在没有正则方法的情况下有泛化能力呢?
如果令 是一个
的样本矩阵,秩为
,无论什么样的
,等式
有无数种解。我们可以解这个线性系统得到上面经验风险最小问题的一个全局最小。但是是否所有的解都有一样的泛化能力?是否有一个方法能决定某个全局最小解比另一个泛化能力好?这篇论文中接着讨论了SGD是如何选择的。SGD对参数的更新可以表示为:
,其中
是步长,
是预测误差。所以如果偏置项为0的话,最后的解肯定可以以这个形式表示:
。如果我们再完全拟合了标签
,那么可以得到
,这个等式有唯一解。可以注意到,这个等式只依赖于样本之间的点积。
当数据少于10w时,这个线性系统可以在一个工作站上求解。这篇论文在MNIST数据集上求解 得到了1.2%的测试误差。在CIFAR10上,使用了高斯核得到了46%的测试误差。论文里做了一些处理以后,这两个性能还能提升。而且论文里还说加正则并不能提高多少性能。总而言之,论文求解方程得到一个完全拟合训练集的线性模型,而这个线性模型泛化能力还不错。
写在最后:
这篇论文作为一篇颇有争议的best paper,我只能按照我理解的论文思路对内容进行了梳理,论文中一些模棱两可的内容并没有包含在内。如果有兴趣的话,可以阅读原文。最后再按我的理解总结一下,论文要讨论的是神经网络的泛化能力从何而来。
先用神经网络暴力拟合开始,实验神经网络有能力对数据进行暴力拟合(虽然这一点本身就有争议。。),这一点是想说明神经网络复杂度确实很高,也有能力学成一个泛化能力很差的模型。
接着论文考察了一下一般正则化方法对泛化能力的提升,发现提升有限;没有正则化方法,网络也能有一个还行的泛化能力。结合前一个实验,这说明网络虽然可以暴力拟合,但是一般情况下,它并没有这么干。
所以问题就来了:为什么会变成这样呢,明明是有限的训练集,明明有能力暴力拟合数据的,本该就这样直接记住训练集的,为什么你还学到了泛化能力。。
最后以线性模型为例(这一点也有很多不服的),认为SGD的过程本身带有一个隐含的正则效果。就是说优化方法本身限制了模型的解空间,使得学到的模型有一个基础的泛化能力。