TensorFlow教程翻译 | Neural Machine Translation(seq2seq) Tutorial
由ypyu创建,最终由ypyu 被浏览 10 用户
写在前面:读TensorFlow的这篇官网教程,给了我很大的帮助,该教程对seq2seq模型在理论上和代码实现上都有简要介绍。感觉有必要翻译一下做个记录,文章很长,不会做到一字一句的翻译,有些不好翻译的地方我会给出原句,有不严谨的地方望谅解。
本文目录:
- 前沿 | Introduction
- 基础 | Basic
- 训练- 如何构建我们的第一个NMT系统
- 词向量 | Embedding
- 编码器 | Encoder
- 解码器 | Decoder
- 损失 | Loss
- 梯度计算和优化 | Gradient computation & optimization
- 实战 - 训练一个 NMT 模型
- Inference - 如何得到翻译结果
- Intermediate
- 注意力机制的基本知识
- Attention Wrapper API
- 实战 - 构建一个 attention-based NMT 模型
- 技巧和陷阱 | Tips & Tricks
- 数据输入管道 | Data Input Pipeline
- 让 NMT 模型更完美的其他技巧
- 双向 RNNs | Bidirectional RNNs
- Beam Search
- 超参数 | Hyperparameters
- 多 GPU 训练 | Multi-GPU training
- Benchmarks
- 其他资源 | Other resources
- 参考资料 | References
该教程需要TensorFlow1.4版本。提醒:非1.4版本的TensorFlow有一个关于Beam Search的bug fix。
前言 | Introduction
Seq2seq 模型 (Sutskever et al., 2014, Cho et al., 2014) 在机器翻译、语音识别、文本摘要等领域取得了巨大的成功。这篇教程将帮助读者完全理解 seq2seq 模型并学会搭建一个完整的 seq2seq 模型。我们会以神经机器翻译(NMT)为例,因为 seq2seq 模型最先应用于 NMT 并取得了成功。我们给出的代码简洁、质量高且可直接拿来使用,并且吸收了最新的研究成果。我们所做的工作包括:
- 使用最新的 decoder / attention wrapper API,TensorFlow 1.2 data iterator
- 在构建模型时加入了我们最成功的经验
- 为构建最强大的 NMT 模型,我们提供了许多 tips 和 tricks,并复制了Google的 NMT系统
我们提供了一下语料:
- Small-scale: English-Vietnamese parallel corpus of TED talks (133K sentence pairs) provided by the IWSLT Evaluation Campaign.
- Large-scale: German-English parallel corpus (4.5M sentence pairs) provided by the WMT Evaluation Campaign.
我们首先为 NMT 介绍了关于seq2seq的基础知识,解释如何构建并训练一个 vanilla NMT 模型。然后深入细节的详细介绍如何构建一个完整的带有注意力机制的 NMT 模型。然后我们将讨论一些 ticks 和 tips,包括 batching, bucketing , bidirectional RNNs, beam search 以及如何使用多 GPU,这将帮助提高 NMT 模型的训练速度和质量。
基础 | Basic
神经机器翻译的相关背景 | Background on Neural Machine Translation
传统的 phrase-based 翻译系统的工作原理是把源句子分成几块,然后一个短语一个短语的翻译,但是翻译结果的流畅度较差,并且不符合人类的翻译方式,我们人类会读取完整的句子,理解它的意思,然后进行翻译。NMT 模型正是在模仿这个机制!
 图1. Encoder-decoder 结构 - encoder 把源句子转化为一个“有意义”的vector,然后这个vector被decoder解码,得到翻译结果
图1. Encoder-decoder 结构 - encoder 把源句子转化为一个“有意义”的vector,然后这个vector被decoder解码,得到翻译结果
NMT模型使用encoder读取源句子,然后编码得到一个“有意义”的 vector,即一串能代表源句子意思的数字。然后 decoder 将这个 vector 解码得到翻译,就想图1展示的那样。这就是所谓的 encoder-decoder 结构。用这种方式,NMT 解决了在传统的 phrase-based 的翻译模型中所存在的局部翻译的问题(local translation problem),它能够捕捉到语言中更长久的依赖关系,比如性别认同(gender agreements)、句法结构等,然后得到更流畅的翻译结果。
NMT 模型有很多不同的结构,一个自然的选择是使用 RNN,大部分的 NMT 模型都使用RNN。通常,encoder 和 decoder 都会使用 RNN。另外,不同的 RNN 模型也有一些差异:
(a)方向:单向的 或 双向的;
(b)深度:单层的 或 多层的;
(c)类型:vanilla RNN 或 LSTM 或 GRU;
对此感兴趣的读者可以从这篇博客(Understanding LSTM)获取更多关于 RNNs 或 LSTM 的知识。
本教程将以单向的多层(multi-layer) RNN 为例,其使用 LSTM 作为 RNN 单元。图2展示了这样一个模型的例子。这个例子中,我们构建了一个模型把源句子“I am a student”翻译成目标句子“Je suis étudiant”。NMT 模型包含了两个循环神经网络:encoder RNN 只对源句子进行编码而没有做任何的预测;decoder 在预测下一个单词的时候使用了目标句子(译者注:原句就是这么说的,但是我想他所表达的意思应该是预测下一个单词时用到了之前预测出的单词)。
想要获取更多的知识,请看Luong(2016),我们也是基于此完成此教程。
 图2. 神经机器翻译 - 一个把源句子“I am a student” 翻译成 “Je suis étudiant”的模型结构。其中""表示解码的开始,“”表示解码的结束。
图2. 神经机器翻译 - 一个把源句子“I am a student” 翻译成 “Je suis étudiant”的模型结构。其中""表示解码的开始,“”表示解码的结束。
训练- 如何构建我们的第一个NMT系统
Traning - How to build our first NMT system
我们将用非常简洁的代码来更细致的解释图2所示的 RNN 结构,并构建一个 NMT 模型。后面我们会给出数据准备和完整的代码,这部分请参看 model.py。
在最底层,encoder 和 decoder RNNs 按照这样的顺序接收数据:首先是源句子,然后是标记“\<s>”,该标记标志着从编码阶段转换到解码阶段,然后就是目标句子。在训练过程中,我们将把以下 tensors feed 给系统,这些 tensors 都是 time-major 格式的,且其元素是句子索引:
- encoder_inputs [max_encoder_time, batch_size]: source input words.
- decoder_inputs [max_decoder_time, batch_size]: target input words.
- decoder_outputs [max_decoder_time, batch_size]: target output words, 它们是 decoder_inputs 左移了一步,然后右边加了一个标识句子结束的标识。
为了效率,我们会一次训练多个(batch_size)句子。测试时稍有不同,我们后边会讨论。
译者补充:所谓 time-major 格式的 tensor 是指把 max_encoder_time 放在第一维度,即 [max_encoder_time, batch_size],还有 batch-major 是把 batch_size 放在第一维度,即 [batch_size, max_encoder_time]。
词向量 | Embedding
对于给定的自然语言的单词,模型必须首先得到源句子和目标句子的词向量,以检索得到一致的词向量表示(译者注:此句翻译的不好。原句是:Given the categorical nature of words, the model must first look up the source and target embeddings to retrieve the corresponding word representations)。要实现这个目标,每种语言都要有一个词典,通常,词典大小 V 是被人为设定的,并且只有频率最高的 V 个单词会被当做唯一,其他所有的单词会被转换为“unknown”,并且共享同一个词向量。每种语言词向量的值是不同的,这通常会在训练过程中进行学习。
# Embedding
embedding_encoder = variable_scope.get_variable(
"embedding_encoder", [src_vocab_size, embedding_size], ...)
# Look up embedding:
# encoder_inputs: [max_time, batch_size]
# encoder_emb_inp: [max_time, batch_size, embedding_size]
encoder_emb_inp = embedding_ops.embedding_lookup(
embedding_encoder, encoder_inputs)
同样,我们也可以构建 embedding_decoder 和 decoder_emb_inp。当然,你也可以选择使用 word2vec 或 Glove 训练的 vector 来初始词向量。
编码器 | Encoder
词向量一旦被检索到就会被输入到神经网络中,该神经网络包含了两个多层的 RNNs,一个与源语言相关的 encoder 和一个与目标语言相关的 decoder。原则上,这两个 RNNs 可以共享参数;但是实际中,我们使用两套不同的 RNN parameters(such models do a better job when fitting large training datasets)。Encoder RNN 使用零向量作为它的初始状态(starting states),代码如下:
# Build RNN cell
encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
# Run Dynamic RNN
# encoder_outpus: [max_time, batch_size, num_units]
# encoder_state: [batch_size, num_units]
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_emb_inp,
sequence_length=source_sequence_length, time_major=True)
不同的句子可能有不同的长度,为了避免计算资源的浪费,我们把源句子的长度 source_sequence_length 告诉 dynamic_rnn。因为我们的输入是 time major,所以我们设置 time_major=True。这里,我们只构建了一个单层的 LSTM,encoder_cell。在后面的章节中,我们将会讲述如何构建一个多层的 LSTMs,还有使用 dropout 和 attention。
解码器 | Decoder
Decoder 同样需要用到源句子的信息,一个简单的方法是使用 encoder 最后的隐藏层状态 (hidden state), encoder_state,来初始化 decoder。在图2中,我们把在源句子单词“student”位置的隐藏层状态(hidden state)传给了 decoder。
# Build RNN cell
decoder_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
# Helper
helper = tf.contrib.seq2seq.TrainingHelper(
decoder_emb_inp, decoder_lengths, time_major=True)
# Decoder
decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell, helper, encoder_state,
output_layer=projection_layer)
# Dynamic decoding
outputs, _ = tf.contrib.seq2seq.dynamic_decode(decoder, ...)
logits = outputs.rnn_output
这部分代码的核心是 BasicDecoder 的对象 decoder,decoder 接收了 decoder_cell(类似 encoder_cell)、一个 helper 以及 encoder_state 作为输入。By separating out decoders and helpers, we can reuse different codebases(这句没怎么懂). GreedyEmbeddingHelper 可以替换 TrainingHelper 来实现 greedy decoding. 见代码 helper.py 获取更多。
最后,我们还有实现 projection_layer,这是一个稠密矩阵(dense matrix),用来把顶部的隐藏状态(top hidden states)转换为 V 维的 logit vecotrs。参照图2的例子。
projection_layer = layers_core.Dense(
tgt_vocab_size, use_bias=False)
损失 | Loss
有了上述的 logits,下面我们可以计算训练损失了:
crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=decoder_outputs, logits=logits)
train_loss = (tf.reduce_sum(crossent * target_weights) /
batch_size)
其中,target_weights 是一个 0-1 矩阵,其 size 与 decoder_outputs 相同。它用0来 mask 那些超过目标句子长度的 padding 的位置。
Important note: It's worth pointing out that we divide the loss by batch_size, so our hyperparameters are "invariant" to batch_size. Some people divide the loss by (batch_size * num_time_steps), which plays down the errors made on short sentences. More subtly, our hyperparameters (applied to the former way) can't be used for the latter way. For example, if both approaches use SGD with a learning of 1.0, the latter approach effectively uses a much smaller learning rate of 1 / num_time_steps.
重要提示:需要指出的是我们用 loss 除了个 batch_size,所以我们的超参数对 batch_size 来讲是“不变的”(不相关的)。有些人用 loss 除以 (batch_size * num_time_steps),这样做会减少在短句子上产生的错误。 More subtly, our hyperparameters (applied to the former way) can't be used for the latter way (译者注:这句明白啥意思,有看懂望指点). 例如,如果两种方法都使用学习率为 1.0 的 SGD 优化算法,那么后种方法实际上使用的是一个更小的学习率 1 / num_time_steps.
梯度计算和优化 | Gradient computation & optimization
现在我们已经定义了 NMT 模型的前向训练过程,反向传播过程就是几行代码的事:
# Calculate and clip gradients
params = tf.trainable_variables()
gradients = tf.gradients(train_loss, params)
clipped_gradients, _ = tf.clip_by_global_norm(
gradients, max_gradient_norm)
训练 RNNs 最终的一步之一就是梯度截断(gradient clipping)。这里,我们使用 global norm 做截断。Max_gradient_norm 通常设置为像 5 或 1 这样的值。最后一步是选择优化器(optimizer),Adam 优化器用的比较多。我们还要设置学习率。学习率的范围一般为 0.0001 到 0.001,并且还可以设置随着训练的进行而减小。
# Optimization
optimizer = tf.train.AdamOptimizer(learning_rate)
update_step = optimizer.apply_gradients(
zip(clipped_gradients, params))
在我们的实验中,我们使用标准 SGD(tf.train.GradientDescentOptimizer),学习率会随时间下降,因为这样训练效果会更好。
实战 - 训练一个 NMT 模型
Hands-on - Let's train an NMT model
让我们来训练我们的第一个 NMT 模型,把越南语(Vaietnamese)翻译成英语(English)!完整的代码见 nmt.py。
我们使用一个关于 TED talks 的小规模的平行语料(133K 的训练数据),数据可见 https://nlp.stanford.edu/projects/nmt/。我们将使用 tst2012 作为我们的 dev 数据集,使用 tst2013 作为 test数据集。
用下面的命令下载数据:\ nmt/scripts/download_iwslt15.sh /tmp/nmt_data
运行下面的命令开始训练:
mkdir /tmp/nmt_model
python -m nmt.nmt \
--src=vi --tgt=en \
--vocab_prefix=/tmp/nmt_data/vocab \
--train_prefix=/tmp/nmt_data/train \
--dev_prefix=/tmp/nmt_data/tst2012 \
--test_prefix=/tmp/nmt_data/tst2013 \
--out_dir=/tmp/nmt_model \
--num_train_steps=12000 \
--steps_per_stats=100 \
--num_layers=2 \
--num_units=128 \
--dropout=0.2 \
--metrics=bleu
上面的命令训练了一个有 2 层 LSTM 的 seq2seq 模型,隐藏层和词向量都是128维,共训练 12 个 epoch。我们使用 0.2 的 dropout(保留概率0.8)。如果没有错误,我们应该看到与下面展示的类似的 logs,它的困惑度(perplexity)随着训练不断下降。
# First evaluation, global step 0
eval dev: perplexity 17193.66
eval test: perplexity 17193.27
# Start epoch 0, step 0, lr 1, Tue Apr 25 23:17:41 2017
sample train data:
src_reverse: </s> </s> Điều đó , dĩ nhiên , là câu chuyện trích ra từ học thuyết của Karl Marx .
ref: That , of course , was the <unk> distilled from the theories of Karl Marx . </s> </s> </s>
epoch 0 step 100 lr 1 step-time 0.89s wps 5.78K ppl 1568.62 bleu 0.00
epoch 0 step 200 lr 1 step-time 0.94s wps 5.91K ppl 524.11 bleu 0.00
epoch 0 step 300 lr 1 step-time 0.96s wps 5.80K ppl 340.05 bleu 0.00
epoch 0 step 400 lr 1 step-time 1.02s wps 6.06K ppl 277.61 bleu 0.00
epoch 0 step 500 lr 1 step-time 0.95s wps 5.89K ppl 205.85 bleu 0.00
更多的代码见 train.py。
我们可以使用 TensorBoard 来查看模型训练过程中的 summary:
tensorboard --port 22222 --logdir /tmp/nmt_model/
如果想使用越南语翻译成英语的方式训练,可以简单的修改:\ --src=en --tgt=vi。
译者注:我们可以修改 nmt/scripts/download_iwslt15.sh 文件中的 vi,改成 cn,这样就可以用中文训练了。
Inference - 如何得到翻译结果
Inference - How to generate translations
当你训练你的 NMT 模型的时候(或者你已经有训练好的模型),你就可以通过给定的源句子得到其翻译结果了。这个过程叫做 inference。Training 和 inference(testing) 之间有一个明显的区别就是:inference 的时候,我们只会用到源句子,也就是 encoder_inputs。Decoding 过程有很多种方法,包括 greedy,sampling,以及 beam-search decoding。这里我们讨论下 greedy decoding。
想法非常简单,我们以图3为例。
 图3. Greedy decoding - 展示了如何使用一个训练好的 NMT 模型使用 greedy search 由源句子“Je suis étudiant”得到其翻译
图3. Greedy decoding - 展示了如何使用一个训练好的 NMT 模型使用 greedy search 由源句子“Je suis étudiant”得到其翻译
- 使用与训练时同样的方法对源句子进行编码得到 encoder_state,并且用这个 encoder_state 来初始化 decoder。
- 在 decoder 接收到开始符号“\<s>”(代码中的 tgts_sos_id)的时候,解码(翻译)的过程开始。
- 对于 decoder 的每个 timestep,我们都把 RNN 的输出当做一个 logits 的集合,并从中选择出最有可能的单词,我们把 logit 值最大的那个单词的 id 作为最有可能的单词(这就是所谓“贪心”)。像图3中的例子,单词“moi”在 decoding 的第一步拥有最高的可能,我们就把这个单词输入到下一步的翻译中。
- 这个过程会一直持续,直到句子结束的标记“\</s>”作为输出字符出现(代码中的 tgt_eos_id)。
第三步是与训练不一样的地方,训练时,输入的始终是正确的目标单词,而在 inference 时,输入的是模型预测出的单词。下边是 greedy decoding 的代码,与 training decoder 非常相似:
# Helper
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(
embedding_decoder,
tf.fill([batch_size], tgt_sos_id), tgt_eos_id)
# Decoder
decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell, helper, encoder_state,
output_layer=projection_layer)
# Dynamic decoding
outputs, _ = tf.contrib.seq2seq.dynamic_decode(
decoder, maximum_iterations=maximum_iterations)
translations = outputs.sample_id
这里,我们使用 GreedyEmbeddingHelper 代替 TrainingHelper。因为我们不能预知目标句子的长度,所以使用 maximum_iterations 来限制翻译句子的长度。一种启发式的做法是让令 maximum_iterations 为源句子长度的两倍。
maximum_iterations = tf.round(tf.reduce_max(source_sequence_length) * 2)
有了训练好的模型,我们就可以创建一个 inference 文件并且尝试翻译一些句子啦:
cat > /tmp/my_infer_file.vi
# (copy and paste some sentences from /tmp/nmt_data/tst2013.vi)
python -m nmt.nmt \
--out_dir=/tmp/nmt_model \
--inference_input_file=/tmp/my_infer_file.vi \
--inference_output_file=/tmp/nmt_model/output_infer
cat /tmp/nmt_model/output_infer # To view the inference as output
注意上边这个命令也可以在训练过程中运行,只要本地已经保存了一个训练的 checkpoint。更多细节见 inference.py。
(这个中文咋翻译好?) | Intermediate
学习了这个最基本的 seq2seq 模型,让我们玩点高级的!构建一个能达到业界最好水平的神经机器翻译系统,我们需要一些“秘密的调味”:注意力机制。注意力机制最先由 Bahdanau et al., 2015 提出,后来又被 Luong et al., 2015 等人继续完善。 注意力机制最关键的地方在于通过在翻译时把“注意力”放在相关的源句子单词上的方式,在目标句子和源句子之间建一个直接相连的捷径(direct short-up connections)。注意力机制的一个非常漂亮的技巧在于可以非常容易的可视化源句子与目标句子之间的对齐矩阵(alignment matrix),见图4.
 图四. Attention visualization - example of the alignments between source and target sentences. Image is taken from (Bahdanau et al., 2015)
图四. Attention visualization - example of the alignments between source and target sentences. Image is taken from (Bahdanau et al., 2015)
还记得吗,在 vanilla seq2seq 模型中,我们在编码开始的时候把 encoder 最后的状态(state)传给 decoder,这种方法对于中短的句子来说效果还好。但是对于长句子,这种单一的固定大小的隐藏状态(single fixed-size hidden state)就变成了信息瓶颈(information bottleneck)。
与丢弃 source RNN 中所有的隐藏状态不同,注意力机制提供了一种 decoder “偷看”这些隐藏状态的方法(把它们当做源句子信息的动态内存)。通过这种方法,注意力机制提升了长句子的翻译效果。现在注意力机制已经成为了一种事实上的标准,并且已经成功的应用于许多其他的任务(包括图片说明生成,语音识别,文本摘要)。
注意力机制的基本知识
Backgound on the Attention Mechanism
我们简要叙述了(Luong et al., 2015)提出的注意力机制模型,该模型已经被应用于几个达到业界最好水平的系统,比如开源的工具包 OpenNMT 以及本教程中的 TF seq2seq API.
 图5. 注意力机制 -(Luong et al., 2015)中 attention-based NMT 系统的一个例子。我们高亮了attention计算的第一步(We highlight in detail the first step of the attention computation.)。简单起见,我们没有展示如图2所示的词向量和 projection layer.
图5. 注意力机制 -(Luong et al., 2015)中 attention-based NMT 系统的一个例子。我们高亮了attention计算的第一步(We highlight in detail the first step of the attention computation.)。简单起见,我们没有展示如图2所示的词向量和 projection layer.
正如图5所展示的, decoder 的每一步都会有 attention 的计算。计算过程如下:
- The current target hidden state is compared with all source states to derive attention weights (can be visualized as in Figure 4).
- Based on the attention weights we compute a context vector as the weighted average of the source states.
- Combine the context vector with the current target hidden state to yield the final attention vector
- The attention vector is fed as an input to the next time step (input feeding). The first three steps can be summarized by the equations below
- 当前目标隐藏状态与所有的源句子中的状态进行比较计算,得到 attention 权重(正如图四所展示的)。
- 基于1中得到的 attention 权重,通过加权平均计算源句子状态的 context vector。
- 由 context vector 和当前目标隐藏状态得到最后的 attention vector。
- 把这个 attention vector 当做输入数据喂给下一步的计算。前述的三个步骤可以用下边三个等式来总结:
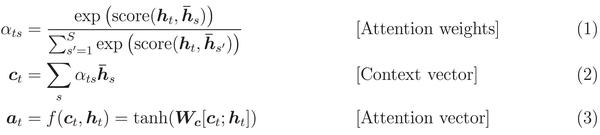 其中,函数 score 用来比较计算目标隐藏状态
其中,函数 score 用来比较计算目标隐藏状态
$h_{t}$
和每个源句子的隐藏状态
$\bar{h}_{s}$
,然后归一化得到 attention 权重(一个在所有源句子单词位置上的分布)。这个 scoring 函数的计算方法有很多,公式4中的乘法和加法的方式是比较常用的。得到 attention vector
$a_{t}$
之后,就可以用来计算 softmax logit 和 loss了。这与上述的 vanilla seq2seq 模型顶层的目标隐藏状态计算方法相似,函数
$f$
也可以采用其他的形式:
 更多的 attention 机制的实现方式可见 attention_wrapper.py.
更多的 attention 机制的实现方式可见 attention_wrapper.py.
what matters in the attention mechanism?
注意力机制最关键的是啥?
As hinted in the above equations, there are many different attention variants. These variants depend on the form of the scoring function and the attention function, and on whether the previous state ht−1 is used instead of ht in the scoring function as originally suggested in (Bahdanau et al., 2015). Empirically, we found that only certain choices matter. First, the basic form of attention, i.e., direct connections between target and source, needs to be present. Second, it's important to feed the attention vector to the next timestep to inform the network about past attention decisions as demonstrated in (Luong et al., 2015). Lastly, choices of the scoring function can often result in different performance. See more in the benchmark results section.
中文翻译(仅供参考):如上所说,还有很多不同的 attention 变种。他们的区别在于 scoring 函数、attention 函数的不同,以及是否在 scoring 函数中中使用前一步状态
$h_{t-1}$
替换
$h_{t}$
,正如(Bahdanau et al., 2015)最开始建议的那样。根据经验,我们发现只有你的实际选择才是注意力机制的关键。首先,注意力机制最基本的形式,也就是目标句子与源句子之间的连接,是必须要遵守和实现的。其次,正如(Luong et al., 2015)所提到的,在下一步计算时把 attention vector 传入是非常重要的,它可以为神经网络提供一些之前的“attention的选择”。最后,不同的 scoring 函数的选择会得到不同的翻译效果。可参考 benckmark results 小节。
Attention Wrapper API
在 AttentionWrapper 的实现中,我们借鉴了 (Weston et al., 2015) 中关于 memory network 的一些技巧。在本教程中,我们使用 read-only memory 来替换 readable & writable memory. 所谓的 “memory”其实就是源句子隐藏状态的集合(或者是 Luong的scoring 中的转换版本,即
$W\bar{h}_{s}$
,或Bahdanau 中的版本
$W_{2}\bar{h}_{s}$
)。每一步,我们使用当前目标隐藏状态作为“query”来决定读取 memory 的哪一部分。通常,这个 query 要与 memory 的每个位置的“关键值”进行比较计算,在我们上述的注意力机制中,我们把源句子的隐藏状态(或其转换版本)当做这个“关键值”。你可以根据这个 memory-network 技术来提出更多的 attention 的形式。
有了 attention wrapper,由 vanilla seq2seq 的代码得到 attention 版本就非常简单啦。这部分代码见 attention_model.py。
首先,我们需要定义一种 attention 机制,比如(Luong et al., 2015):
# attention_states: [batch_size, max_time, num_units]
attention_states = tf.transpose(encoder_outputs, [1, 0, 2])
# Create an attention mechanism
attention_mechanism = tf.contrib.seq2seq.LuongAttention(
num_units, attention_states,
memory_sequence_length=source_sequence_length)
在前面的 Encoder 小节,encoder_outputs 是顶层的所有源句子单词的隐藏状态的集合,其shape 是 [max_time, batch_size, num_units](因为我们使用 dynamic_rnn,为了高效,所以设置 time_major=True)。为实现 attention 机制,我们需要保证 “memory”是 batch major的,所以我们需要用 transpose 转换 attention_states 的 shape。我们还用到了 source_sequence_length ,以确保 attention 权重能正确的被归一化(只归一化没有padding 0的位置)。
定义 attention 机制之后,我们使用 AttentionWrapper 来 wrap 这个 decoding cell:
decoder_cell = tf.contrib.seq2seq.AttentionWrapper(
decoder_cell, attention_mechanism,
attention_layer_size=num_units)
其余代码可见 Decoder 小节。
实战 - 构建一个 attention-based NMT 模型
Hands-on - building an attention-based NMT model
为了能使用 attention,在训练过程中我们使用 luong, scaled_luong, bahdanau 和 normed_bahdanau 中的一种作为 attention 的标记的值。这个attention 标记是指我们要使用哪种类型的 attention 机制。另外,我们为 attention 模型创建了一个新的目录,所以,我们就不复用之前训练的那个 NMT 模型了。
运行以下命令来开始训练:
mkdir /tmp/nmt_attention_model
python -m nmt.nmt \
--attention=scaled_luong \
--src=vi --tgt=en \
--vocab_prefix=/tmp/nmt_data/vocab \
--train_prefix=/tmp/nmt_data/train \
--dev_prefix=/tmp/nmt_data/tst2012 \
--test_prefix=/tmp/nmt_data/tst2013 \
--out_dir=/tmp/nmt_attention_model \
--num_train_steps=12000 \
--steps_per_stats=100 \
--num_layers=2 \
--num_units=128 \
--dropout=0.2 \
--metrics=bleu
训练结束之后,我们使用相同的 inference 命令来进行预测,当然 out_dir 要进行修改:
python -m nmt.nmt \
--out_dir=/tmp/nmt_attention_model \
--inference_input_file=/tmp/my_infer_file.vi \
--inference_output_file=/tmp/nmt_attention_model/output_infer
Tips & Tricks
技巧和陷阱
Building Training, Eval and Inference Graphs
构建训练、验证和测试图
当我们使用 TensorFlow 单间一个机器学习模型的时候,最好构建三个分开的 graph:
- 训练图,包括:
- Batches, buckets, 以及来自文件或外部输入的数据集的部分采样数据;
- 前向和反向传播的 ops;
- 创建 optimizer,以及添加训练 op;
- 验证图,包括:
- Batches, buckets, 以及来自文件或外部输入的数据集输入数据
- 训练时的前向传播 op,以及要添加的 evaluation ops
- 预测图,包括:
- 不需要批处理的输入数据
- 不需要 subsample 和 bucket 输入数据
- 从 placeholders 读取输入数据(数据可以通过 feed_dict 被图读取,或者使用 C++ TensorFlow serving binary)
- 模型前向传播的部分 ops,以及一些可能 session.run 函数调用的所需要的额外的为存储状态(state)所需要的 inputs/outputs。
原文:
- The Training graph, which:
- Batches, buckets, and possibly subsamples input data from a set of files/external inputs.
- Includes the forward and backprop ops.
- Constructs the optimizer, and adds the training op.
- The Eval graph, which:
- Batches and buckets input data from a set of files/external inputs.
- Includes the training forward ops, and additional evaluation ops that aren't used for training.
- The Inference graph, which:
- May not batch input data.
- Does not subsample or bucket input data.
- Reads input data from placeholders (data can be fed directly to the graph via feed_dict or from a C++ TensorFlow serving binary).
- Includes a subset of the model forward ops, and possibly additional special inputs/outputs for storing state between session.run calls.
现在比较棘手的一点是 ,如何在一个机器上让三个图共享这些 variables,这可以通过为每个图创建不同的 session 来解决。训练过程的session 周期性的保存 checkpoints,然后 eval session 和 inference session 就可以读取checkpoints。下面的例子展示了这两种方法的不同。
前一种方法:三个模型都在一个图里,并且共享一个 session。
with tf.variable_scope('root'):
train_inputs = tf.placeholder()
train_op, loss = BuildTrainModel(train_inputs)
initializer = tf.global_variables_initializer()
with tf.variable_scope('root', reuse=True):
eval_inputs = tf.placeholder()
eval_loss = BuildEvalModel(eval_inputs)
with tf.variable_scope('root', reuse=True):
infer_inputs = tf.placeholder()
inference_output = BuildInferenceModel(infer_inputs)
sess = tf.Session()
sess.run(initializer)
for i in itertools.count():
train_input_data = ...
sess.run([loss, train_op], feed_dict={train_inputs: train_input_data})
if i % EVAL_STEPS == 0:
while data_to_eval:
eval_input_data = ...
sess.run([eval_loss], feed_dict={eval_inputs: eval_input_data})
if i % INFER_STEPS == 0:
sess.run(inference_output, feed_dict={infer_inputs: infer_input_data})
后一种方法:三个模型在三个图里,三个 sessions 共享同样的 variables。
train_graph = tf.Graph()
eval_graph = tf.Graph()
infer_graph = tf.Graph()
with train_graph.as_default():
train_iterator = ...
train_model = BuildTrainModel(train_iterator)
initializer = tf.global_variables_initializer()
with eval_graph.as_default():
eval_iterator = ...
eval_model = BuildEvalModel(eval_iterator)
with infer_graph.as_default():
infer_iterator, infer_inputs = ...
infer_model = BuildInferenceModel(infer_iterator)
checkpoints_path = "/tmp/model/checkpoints"
train_sess = tf.Session(graph=train_graph)
eval_sess = tf.Session(graph=eval_graph)
infer_sess = tf.Session(graph=infer_graph)
train_sess.run(initializer)
train_sess.run(train_iterator.initializer)
for i in itertools.count():
train_model.train(train_sess)
if i % EVAL_STEPS == 0:
checkpoint_path = train_model.saver.save(train_sess, checkpoints_path, global_step=i)
eval_model.saver.restore(eval_sess, checkpoint_path)
eval_sess.run(eval_iterator.initializer)
while data_to_eval:
eval_model.eval(eval_sess)
if i % INFER_STEPS == 0:
checkpoint_path = train_model.saver.save(train_sess, checkpoints_path, global_step=i)
infer_model.saver.restore(infer_sess, checkpoint_path)
infer_sess.run(infer_iterator.initializer, feed_dict={infer_inputs: infer_input_data})
while data_to_infer:
infer_model.infer(infer_sess)
注意后一种方法是如何被转换为分布式版本的。
后种方法与前种方法的另一个不同在于,后者不用在 session.sun 调用时通过 feed_dicts 喂给数据,而是使用自带状态的 iterator 对象(stateful iterator objects)。不论在单机还是分布式集群上,这些 iterators 可以让输入管道(input pipeline)变得更容易。在下一小节,我们将使用新的数据输入管道(input data pipeline)。
数据输入管道 | Data Input Pipeline
在 TensorFlow 1.2版本之前,用户有两种把数据喂给 TensorFlow training 和 eval pipelines的方法:
- 在每次训练调用 session.run 时,通过 feed_dict 直接喂给数据;
- 使用 tf.train(例如 tf.train.batch)和 tf.contrib.train 中的队列机制(queueing machanisms);
- 使用来自 helper 层级框架比如 tf.contrib.learn 或 tf.contrib.slim 的 helpers (这种方法是使用更高效的方法利用第二种方法)。
第一种方法对不熟悉 TensorFlow 或需要做一些外部的数据修改(比如他们自己的 minibatch queueing)的用户来说更简单,这种方法只需用简单的 Python 语法就可实现。第二种和第三种方法更标准但也不那么灵活,他们需要开启多个 Python 线程(queue runners)。更重要的是,如果操作不当会导致死锁或难以查明的错误。尽管如此,队列的方法仍要比 feed_dict 的方法高效很多,并且也是单机和分布式训练的标准。
从TensorFlow 1.2开始,有一种新的数据读取的方法可以使用: dataset iterators,其在 tf.data 模块。Data iterators 非常灵活,易于使用和操作,并且利用 TensorFlow C++ runtime 实现了高效和多线程。
我们可以使用一个 batch data Tensor,一个文件名,或者包含多个文件名的 Tensor 来创建一个 dataset。下面是一些例子:
# Training dataset consists of multiple files.
train_dataset = tf.data.TextLineDataset(train_files)
# Evaluation dataset uses a single file, but we may
# point to a different file for each evaluation round.
eval_file = tf.placeholder(tf.string, shape=())
eval_dataset = tf.data.TextLineDataset(eval_file)
# For inference, feed input data to the dataset directly via feed_dict.
infer_batch = tf.placeholder(tf.string, shape=(num_infer_examples,))
infer_dataset = tf.data.Dataset.from_tensor_slices(infer_batch)
所有的数据都可以完成像数据预处理一样的处理方式,包括数据的 reading 和 cleaning,bucketing(在 training 和 eval 的时候),filtering 以及 batching。
把每个句子转换为单词串的向量(vectors of word strings),那我们可以使用 dataset 的 map transformation:
dataset = dataset.map(lambda string: tf.string_split([string]).values)
我们也可以把每个句子向量转换为包含向量与其动态长度的元组:
dataset = dataset.map(lambda words: (words, tf.size(words))
最后,我们可以对每个句子应用 vocabulary lookup。给定一个 lookup 的 table,此 map 函数可以把元组的第一个元素从串向量转换为数字向量。(译者注:不好翻译,原文是:Finally, we can perform a vocabulary lookup on each sentence. Given a lookup table object table, this map converts the first tuple elements from a vector of strings to a vector of integers.)
dataset = dataset.map(lambda words, size: (table.lookup(words), size))
合并两个 datasets 也非常简单,如果两个文件有行行对应的翻译,并且两个文件分别被不同的 dataset 读取,那么可以通过下面这种方式生成一个新的 dataset,这个新的 dataset 的内容是两种语言的翻译一一对应的元组。
source_target_dataset = tf.data.Dataset.zip((source_dataset, target_dataset))
Batching 变长的句子实现起来也很直观。下边的代码从 source_target_dataset 中 batch 了 batch_size 个元素,并且分别为每个 batch 的源向量和目标向量 padding 到最长的源向量和目标向量的长度。
batched_dataset = source_target_dataset.padded_batch(
batch_size,
padded_shapes=((tf.TensorShape([None]), # source vectors of unknown size
tf.TensorShape([])), # size(source)
(tf.TensorShape([None]), # target vectors of unknown size
tf.TensorShape([]))), # size(target)
padding_values=((src_eos_id, # source vectors padded on the right with src_eos_id
0), # size(source) -- unused
(tgt_eos_id, # target vectors padded on the right with tgt_eos_id
0))) # size(target) -- unused
从 dataset 拿到的数据会嵌套为元组,其 tensors 的最左边的维度是 batch_size. 其结构如下:
- iterator[0][0] has the batched and padded source sentence matrices.
- iterator[0][1] has the batched source size vectors.
- iterator[1][0] has the batched and padded target sentence matrices.
- iterator[1][1] has the batched target size vectors.
最后,bucketing 多个 batch 的大小差不多的源句子也是可以的。更多的代码实现详见文件utils/iterator_utils.py。
从 dataset 中读取数据需要三行的代码:创建 iterator,取其值,初始化。
batched_iterator = batched_dataset.make_initializable_iterator()
((source, source_lengths), (target, target_lengths)) = batched_iterator.get_next()
# At initialization time.
session.run(batched_iterator.initializer, feed_dict={...})
一旦 iterator 被初始化,那么 session.run 每一次调用 source 和 target ,都会从dataset中自动提取下一个 minibatch 的数据。
让 NMT 模型更完美的其他技巧
Other details for better NMT models
双向 RNNs | Bidirectional RNNs
一般来讲,encoder 的双向 RNNs 可以让模型表现更好(训练速度会下降,因为有更多的层需要计算)。这里,我们给出了构建一个单层双向层的 encoder 的简单代码:
# Construct forward and backward cells
forward_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
backward_cell = tf.nn.rnn_cell.BasicLSTMCell(num_units)
bi_outputs, encoder_state = tf.nn.bidirectional_dynamic_rnn(
forward_cell, backward_cell, encoder_emb_inp,
sequence_length=source_sequence_length, time_major=True)
encoder_outputs = tf.concat(bi_outputs, -1)
encoder_outputs 和 encoder_state 也可以使用 Encoder 小节的方法获取到。需要注意的是,如果要创建多层双向层,你需要修改一下 encoder_state,见 model.py 的__build_bidirectional_rnn()_ 方法。
Beam Search
Greedy decoding 可以给我们非常合理的翻译结果,但是 beam search decoding 可以让翻译结果更好。Beam search 的思想是,考虑我们可以选择的所有翻译结果的排名最靠前的几个候选的集合,我们探索其所有的可能翻译结果(这里解释的不是很清楚,可以参考知乎的一个讨论:谁能解释下seq2seq中的beam search算法过程?)。Beam 的这个 size 我们称为 beam width,一个较小的 beam width 比如说 10,就已经足够大了。我们推荐读者阅读 Neubig, (2017) 的 7.2.3 小节。这是 beam search 的一个例子:
# Replicate encoder infos beam_width times
decoder_initial_state = tf.contrib.seq2seq.tile_batch(
encoder_state, multiplier=hparams.beam_width)
# Define a beam-search decoder
decoder = tf.contrib.seq2seq.BeamSearchDecoder(
cell=decoder_cell,
embedding=embedding_decoder,
start_tokens=start_tokens,
end_token=end_token,
initial_state=decoder_initial_state,
beam_width=beam_width,
output_layer=projection_layer,
length_penalty_weight=0.0)
# Dynamic decoding
outputs, _ = tf.contrib.seq2seq.dynamic_decode(decoder, ...)
在 Decoder 小节,dynamic_decode() API 也被使用过。解码结束,我们就可以使用下面的代码得到翻译结果:
translations = outputs.predicted_ids
# Make sure translations shape is [batch_size, beam_width, time]
if self.time_major:
translations = tf.transpose(translations, perm=[1, 2, 0])
更多细节,可查看 model.py, _build_decoder() 函数。
超参数 | Hyperparameters
有一些超参数也可以供我们调节。这里,根据我们的实验,我们列举了几个超参数【你可以表示不认同,保留自己的看法】。
- optimizer:对于“不太常见”的网络结构,Adam 可能可以给出一个较合理的结果,如果你用 SGD 进行训练,那么 SGD 往往可以取得更好的结果。
- Attention:Bahdanau 类型的 attention,encoder 需要双向结构才能表现很好;同时 Luong 类型的 attention 需要其他的一些设置才能表现很好。在本教程中,我们推荐使用被改进的这两个类型的 attention:scaled_luong 和 normed_bahdanau。
多 GPU 训练 | Multi-GPU training
训练一个 NMT 模型可能需要几天的时间,我们可以把不同的 RNN layers 放在不同的 GPUs 进行训练可以加快训练速度。这里是使用多 GPUs 创建 RNN layers 的例子:
cells = []
for i in range(num_layers):
cells.append(tf.contrib.rnn.DeviceWrapper(
tf.contrib.rnn.LSTMCell(num_units),
"/gpu:%d" % (num_layers % num_gpus)))
cell = tf.contrib.rnn.MultiRNNCell(cells)
另外,我们还需要 tf.gradients 的 colocate_gradients_with_ops 参数来同步梯度的计算。
你会发现,尽管我们使用了多个 GPUs,但是 attention-based NMT 模型的训练速度提升不大。问题的关键在于,在标准的 attention 模型中,在每个时间步,我们都需要用最后一层的输出去“查询”attention,这就意味着,每一个解码的时间步都需要等前面的时间步完全完成。因此,我们不能简单的通过在多 GPUs 上部署 RNN layers 来同步解码过程。
GNMT attention architecture 可以通过使用第一层的输出来查询 attention 的方法来同步 decoder 的计算。这样,解码器的每一步就可以在前一步的第一层和 attention 计算完成之后就可以进行解码了。我们的 API 实现了这个结构 GNMTAttentionMultiCell,其是_tf.contrib.rnn.MultiRNNCell_ 的子类。这里是使用 GNMTAttentionMultiCell 创建一个 decoder 的例子:
cells = []
for i in range(num_layers):
cells.append(tf.contrib.rnn.DeviceWrapper(
tf.contrib.rnn.LSTMCell(num_units),
"/gpu:%d" % (num_layers % num_gpus)))
attention_cell = cells.pop(0)
attention_cell = tf.contrib.seq2seq.AttentionWrapper(
attention_cell,
attention_mechanism,
attention_layer_size=None, # don't add an additional dense layer.
output_attention=False,)
cell = GNMTAttentionMultiCell(attention_cell, cells)
Benchmarks
这部分就不翻译了,截个图放这吧:






其他资源 | Other resources
想更深入的学习神经机器翻译和 seq2seq 模型,我们强烈推荐这三个参考资料: Luong, Cho, Manning, (2016); Luong, (2016); and Neubig, (2017).
构建 seq2seq 模型有很多不同的工具,所以每种框架我们选了一种:
- Matlab:Stanford NMT
- TensorFlow:tf-seq2seq
- Theano:Nemantus
- Torch:OpenNMT
- PyTorch:OpenNMT-py
参考资料 | References
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. ICLR.
- Minh-Thang Luong, Hieu Pham, and Christopher D Manning. 2015. Effective approaches to attention-based neural machine translation. EMNLP.
- Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. NIPS.
\