《Introduction to Boosted Trees》
由ypyu创建,最终由ypyu 被浏览 11 用户
写在前面:
chentq关于XGBoost的slides,图文并茂,浅显易懂。
一句话简述:
先从有监督学习,回归树等基本概念讲解,然后引入Gradient Boosting的具体内容。
Review of key concepts of supervised learning


以线性模型为例进行讲述,需从数据学习的就是这些参数。


目标是就是学习training loss和regularzation总体最低,前者刻画数据上的表现,后者刻画模型的复杂度,或者说模型的稳定性。并给出几个常用的刻画方式,带入到实际中,具体的目标函数如下:


Regression Tree and Ensemble
首先要有回归树(CART)的知识,对于单棵树:


Ensemble的方式就是将多棵树融合在一起进行预测,示例如下:


具体ensemble的方式很多,如GBM,RF等。对于tree ensemble的目标函数:


对于目标函数,有很多启发式的方法,chentq列举了一些,并给出了其表征的本质(赞):


Gradient Boosting
Additive training每一轮是去拟合前面几轮和label的残差。这是在函数空间中进行求解,而非之前对一个函数在参数空间中进行求解。


这样每轮就是在预测f_t(xi),将其带入obj的一般式中:


若考虑使用square loss:


在展开这个式子的过程中,你会发现少一个项,原因是对于第t轮而言,它是常量,可以归并到后面的const里面了。


再回到之前的一般意义的目标函数上:


为了可以使用梯度下降来对其进行优化,我们对目标函数中的经验损失部分做泰勒展开近似,泰勒二阶展开的一般式为:


对Goal进行二阶展开后的形式如下:


这里define:


为了方便更好的感知,以square loss为例:




移除obj中的常量,最终的Obj形式为:


(这里chentq其实最好应给出二元泰勒公式的二阶展开,因为实际例子是二元的情形。


)
接下来再来说对树复杂度的控制,这里采用了叶子节点个数L2正则,并给出示例:




有了前面两项的描述之后,重新来看下整体的目标:


在第t轮生成树的时候,前面是站在树的角度去看在整体数据的表现;而后者细化成了从叶子节点的角度,分别看落在自己叶子节点上的数据的表现。
对于一般二项式,如下图所示,参数x值为红框所示值时,函数取得最小值,值为绿框所示:


为了看起来方便,将整体Obj做一些参数上的替代:


单个叶子节点上的估量为:


按照上面的知识,该叶子节点权重为如下是,loss最小:


将所有叶子节点汇总后,整棵树的Obj,并给出示例:
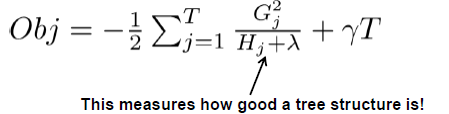



理想查找算法:
1 枚举出所有树的可能性。
2 利用上面整棵树的Obj,来找最优的树。


3 对每个叶子节点赋值:


但显而易见,树的搜索空间非常巨大,想逐个枚举是不可能的。
贪心策略:
在实践中,我们经常使用贪心的方式,即对当前节点进行分裂,若有足够的收益就分裂,否则不分裂。


这里的本质就是,分裂前后的收益大小,分裂的收益越大代表当前feature越适合分裂。最后一项是由于引入了新的节点,使得模型变的复杂了。言外之意就是,当分裂收益比较小时,咱还不如不分裂了,这点收益都不够忙活的了~
如何找到最优分裂点?
具体而言,这个问题包含了两个子问题:
1. 选取哪个特征作为分裂特征?
2 这个特征具体选用什么阈值?


我们当然是选择按照上面描收益最大的特征以及分裂阈值了。这里sort的意义在于对于某个feature,在选择最优分裂阈值时,不必再额外筛选该阈值左右两端的节点了。算法具体如下:


关于时间复杂度的分析:


对于深度为K的树,一共d个feature的数据来说,一个节点上对一个feature进行排序,需要O(n *logn),由于同一层次其他节点可以并行来做,所以一层的复杂度还是O(n *logn),由于每个feature都要sort,有O(d*n *logn),又因为有K层,故O(K*d*n *logn)。
停止条件:


通过以上,基本介绍完全部内容了,我们再来整体回顾下:


谢谢。