斯坦福CS224N深度学习自然语言处理(二)
由ypyu创建,最终由ypyu 被浏览 3 用户
国内视频地址:斯坦福CS224N深度学习自然语言处理课程(二)Word2Vec词向量表示


(这几篇papers后续补充)


(主要介绍Word2Vec,以及TA介绍一篇重要paper。)


(之前表征word的方式,使用分类学的方法,考虑上位词以及同义词集合。这样带来的问题有:)


(对于同义词细微的差别无法满足,确实新词,可能过于人为主观,并需要大量的人工工作,以及很难计算准确度。)
不论是基于大量规则的方式,还是统计性NLP方式,都是在基本词粒度上处理成one-hot形式。


(这种one-hot形式,还不能直接用来处理word之间的关系,虽然向量的点乘操作结果可以表征两个向量的相似程度,但是one-hot的特殊性决定了两个不同word的向量点乘结果为0。)


(因此,需要在one-hot的基础上再进一步的处理。)


(这里给出了一个NLP中简单而又非常好用的假设,即可以通过一个词周围词集合当中提取出有价值的信息。并给出了一个"banking"的例子,想象一下,虽然在大规模语料中,此时这种统计就是非常有价值的了。)


(将之前稀疏的的向量,压缩到一个稠密的向量中,以此来表示该词,至于这里每维特征的意义,对于人来说是感知不出来的,它是在计算机的角度来看的。)
此时,我们的任务就很明晰了,设计一个model来刻画一个词和其context的概率,整体越大说明学习的越好。也可以写成loss形式,此时越销越好。


(接下来给出了上面讨论的这个模型的变迁史:)


(除了即将要介绍的word2vec,建议A neural probabilistic language model (Bengio et al., 2003)最好也读一读。)


(W2V的目的就是找到的word与其context words之间的关联。
主要包括两个模型:SG、CBOW,以及两种训练方法:Hierarchical softmax和Negative sampling)
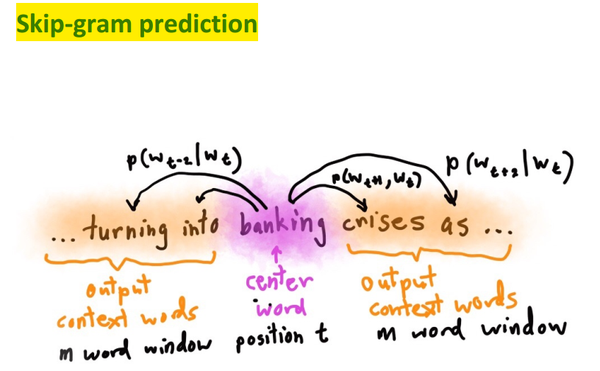

(skip-gram是依靠当前word,预测context,如上所示。)


(具体就是针对每一个word,计算它前后m个邻居。使得整体概率乘积最大,为了方便优化将其写成negative log likelihood形式,将乘法转换成加法。)


(ML中所言的loss function,cost function以及objective function概念上是等价的。
通常对于概率分布选择交叉熵作为loss。但这里使用的向量(即分布)是onehot形式,此时计算结果时只有trueclass对应位置有值,这样的话有些不当)


其中:


(点乘的意义是两个向量越是近似,则点乘结果越大。)


(即用指数的方式来刻画概率,同时在全局上做归一化。)


(此图可以说是skip-gram的精华所在。下面来讲如何训练model,即或得相应参数。)


(如何获得模型,其实就是已知模型结构,如何获得参数。对于每一个word,都会受到上述W和W'两个矩阵的影响,因此就是有d*V+d*V个参数需要优化)
(为了介绍梯度下降,先说下基础数学知识,视频中老师管这个叫baby math~)




(其实就是求导和链式法则。下面才是我们真正的开始。)


(对于1,就是在全量数据上,对于每个word,求其周边m个相邻词的条件概率,使其总和最大化,这里j!=0,是指剔除自身。
对于logp(...),式子2中给出了详细的softmax形式,带入即可。即有:)








(Remind:logx的导数: 以a为底的X的对数 的导数是1/xlna ,以e为底的是1/x;e^x的导数:e^x)
这里的最后形式:其实个人感觉式子1更好记和更好理解。


(后面都是介绍梯度下降:)







