《Ranking Relevance in Yahoo Search》(下)
由iquant创建,最终由iquant 被浏览 7 用户
SEMANTIC MATCHING FEATURES
接下来这部分可以说是搜索引擎中最为重要的部分了,包含了基础语义特征以及点击反馈。
Click Similarity
(点击是搜索引擎中用户反馈最为重要的一个信号,通过点击可以挖掘出极其丰富的数据。)这里是通过点击来构建query和url之间的桥梁。将全量的query和全量的url看作一个庞大的clickgraph,query和url是节点,若是q-u之间存在点击,则有一条边将两者相连,点击次数是这条边的权重。(有节点,有边,有权重,完美~)
从两个不同的url共现的query(即clickquery)中提取出共现的term,可以认为这些term是对该url很好的刻画。并且若是两个url之间的共现的query越多,说明两个url的文本相似度也越相近。与此类似,若是两个query下共同的点击url越多,也说明这两个query文本语义上更相近。
接下来就是如何利用这个clickgraph,设整个term vocabulary为V,将query,doc按照term的频次表征为一个长度为|V|的归一化的初始向量,可以将clickgraph中的信息保存在一个二维的关系矩阵C中,每次query或者doc和这个关系矩阵做矩阵乘法,可以看作query,doc在V上的更新,每次迭代,query会扩展出很多与其相关的term,具体的value表征其重要性,通过多轮迭代最终会达到一个稳定态。
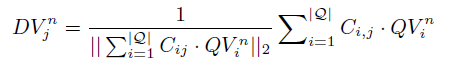



query利用和它有关联的doc和外界沟通;同样,doc也利用和它有关系的query和外界沟通。这里的分母是一个L2正则。
在实践过程中保留所有相关term是不切实际的,因为可能存在很多非常长尾的term,通常只选取Topk的term。通过以上方式刻画出来的query-doc间的feature作为LTR中的一维特征来使用,它的作用是近千维特征中最强的。
Translated Text Matching
前面提及到的click similarity feature虽然作用非常强,但是也存在着缺点,即对click的依赖,只能计量那些在日志中有点击行为的query-doc。这里介绍一下Statistical machine translation(SMT)。


通过将一个query翻译成多个候选query来取max后进行使用。当然也可以反过来,从doc到query,并且也不一定要MAX来生成TTF特征。(广阔天地,大有作为。)
在实践中,这一系列中最有作用的特征是从10个候选项中对cosine取max。
Deep Semantic Matching
The aforementioned CS and TTM features to some extent mitigate the problem: the CS feature smooths the click information and removes the noise of clicks, while the TTM features are the soft version of query rewriting and record the equivalence of n-grams.
Deep learning techniques can help extract semantic and contextual information from top queries, and then we can generalize such information for torso and tail queries.The rareness of torso and tail queries are mainly caused by misspelling,synonyms, abbreviations, long or descriptive queries. Generally speaking, tail queries tend to be substantially longer than top ones.
冷门query相较于热门query长度变长,但表征的语义信息也更多更准。
QUERY REWRITING
query改写主要是为了改善召回的。
Methodology
首先先来说训练数据的获取,人工来标注训练数据很难搞,一是因为人工标注时很难拿捏query之间的相似度;二是所需的数据量太过于庞大。主要还是使用click graph。
Typically titles of documents are very informative and representative while queries are usually very short. Titles are more similar to queries than body texts, which suggests that we consider titles of documents as rewritten queries. These observations motivate us to extract query-title pairs from click graphs.
由于切词粒度不同,对于query中的每一个term都可能有很多种候选改写term,在面对大量的候选改写query时,使用线性模型来选择其中score较大的候选项(paper中说选出最大的,其实不一定一个,可以选择topN个。)刻画候选query_c和原始query之间相似的feature有如下几大类:




Ranking Strategy
Cache the best translation candidate for each query after decoding it. Since the rewrites generated by a given model are constant, the cache entries only expire when a new model is deployed.
(以上阐述的q-u匹配,query改写,click信号的使用等每一个topic都可以说是非常的复杂,这里只是简单说明一下,有兴趣可以看看后面相关的参考文献。接下来再说说搜索引擎重要性也日渐凸显的时间感知与地域感知的内容。)
RECENCY-SENSITIVE RANKING
有些query是有时间感知需求的,例如query=“茅台价格”,给出了一条结果是权威网站结果,title和正文都是讲述茅台,并且也有不错的点击,但偏偏是2002年的网页结果,你认为搜索引擎给了你满意的结果了么?~~~随着现在信息传播越来越发达,越来越多的query在时间维度上的需求日渐凸显。(这句话,有一种好像在写毕设论文的绪论的感觉(・。・))
为了刻画相关性+时效性,进行了五档数据标注,标注时效性query除了考虑其标准以外,还有个地方需要考虑,即标注时的具体时间节点以及当时保存的数据场景,因为此时此刻有时效性需求,随着时间推移会逐渐减弱:
we define a metric called recency-demoted relevance to integrate both relevance and ecency scores. Specifically, for each document, we characterize its recency with a five-level label:“very fresh (VF)”, “fresh (F)”, “slightly outdated (SO)”, “stale (S)” and “non-time-sensitive (NT)”.
为了平衡相关性与时效性,Yahoo!在原有的基于相关性label训练数据获得的树模型基础上,添加了基于时效性数据训练的树模型,x is time-sensitive query-URL pair.:


线下需要将时效性训练数据merge成0/1label,来训练一个binary classifier,以此作为一个开关,来控制r_fresh树模型,到底是加还是不加。
(几点疑问:1 不论预测开关还是树模型r_fresh,都是使用的x,即query-url pair,那么具体特征是哪些?
2 预测query是否有时效性需求和具体url有关吗?难道不是query单方面决定的?
3 只要两个选择,要么加r_fresh,要么不加,会不会过于hard?
4 paper中选择了500个时效性相关的query进行测评,效果不错。但为什么选择有时效性的query来测评呢?这不公平啊,为何没有随机query,冷门突发query的测评,因为这样对相关性是有损的啊。)
LOCATION-SENSITIVE RANKING
与时间感知类似,还有地域感知。query="招行营业点",“海淀家电维修”,用户身在厦门,搜索引擎给了一个广州的招行营业点结果,估计在银行取的钱,都不够来回高铁票钱。
地域感知query分为两类:明确地域指向型query(海淀家电维修),暗含地域指向型query(招行营业点)。
实践中,使用一个刻画是否地域相关的回归函数d(query,url),将这个函数的output作为整个ltr模型中的一个维度。线下实际操作时需要分析query是否有地域需求相关,以及url是否和地域相关。
We first need to extract the locations from both sides.
We parse the location from the explicit local queries and use users’ locations as the query locations for implicit local queries.
The locations of web pages are extracted based on the query-URL click graph from search logs.
Given a URL, we parse the locations from the queries that this URL is connected to, and use these locations to describe the URL.
We keep all the locations as a location vector weighted by the clicks.
In addition, we also parse the locations from URLs directly.Once we have the locations for both queries and URLs, we can easily compute the distance d(QUERY, URL), which is further normalized to the range of [0, 1].
基本上就这么多了,这个paper信息量好大,而且这只是搜索引擎的冰山一角。
嗯,加油。