DeepAlpha实践报告(一)
由small_q创建,最终由small_q 被浏览 615 用户
作者:woshisilvio
DeepAlpha 的优势
deepAlpha的延展性和可塑性。
相比同样的决策树模型还有线性分类模型,deepAlpha无疑具有更大的可扩展空间。 一般的机器学习模型 一旦出现训练数据量过大,又或者面对一些极值数据样本和极端数据差异过大的情况,模型容易陷入过拟合的状态。 模型比较依赖训练的因子特征,如果因子选择不好,会导致模型学习效果不佳,而且在后期难以通过参数去调整学习的效果。
StockRanker绩效:98个因子
而,deepalpha 本身对特征因子的依赖性并不是很大。
原策略只用了3层全连接层网络,结构上还是比较简单,其数据拟合效果已经不输于其他大型的神经网络。就针对同样的特征因子表现来看,deepalpha的效果明显更好。
DeepAlpha原策略绩效图 : 原策略98个因子
优化提升后的策略绩效图:将因子复杂度降低到10个因子。
DeepAlpha不容易过拟合。
从特征表达上来看。 数据量越大,特征因子越多,deepalpha反而不容易过拟合,数据量越大效果模型越稳定。 对原策略中的所有因子 进行单因子回测。 抽取其中一个案例。
单个因子测试绩效:
(数据量增加了2年)
单个因子测试绩效:
回测绩效略有提升,结果反而变好了,当然 只是一段数据的随机回测,由于我测试的样本因子比较少,可能存在偏差。
另外是,对deepalpha预测的样本外股票数据进行20组分组检测,也能看到根据模型的predition得分 进行选股, 尾部的几个分组(因子值大的一端)确实具备一定的预测能力。
DeepAlpha 的改进
提升性能不明显
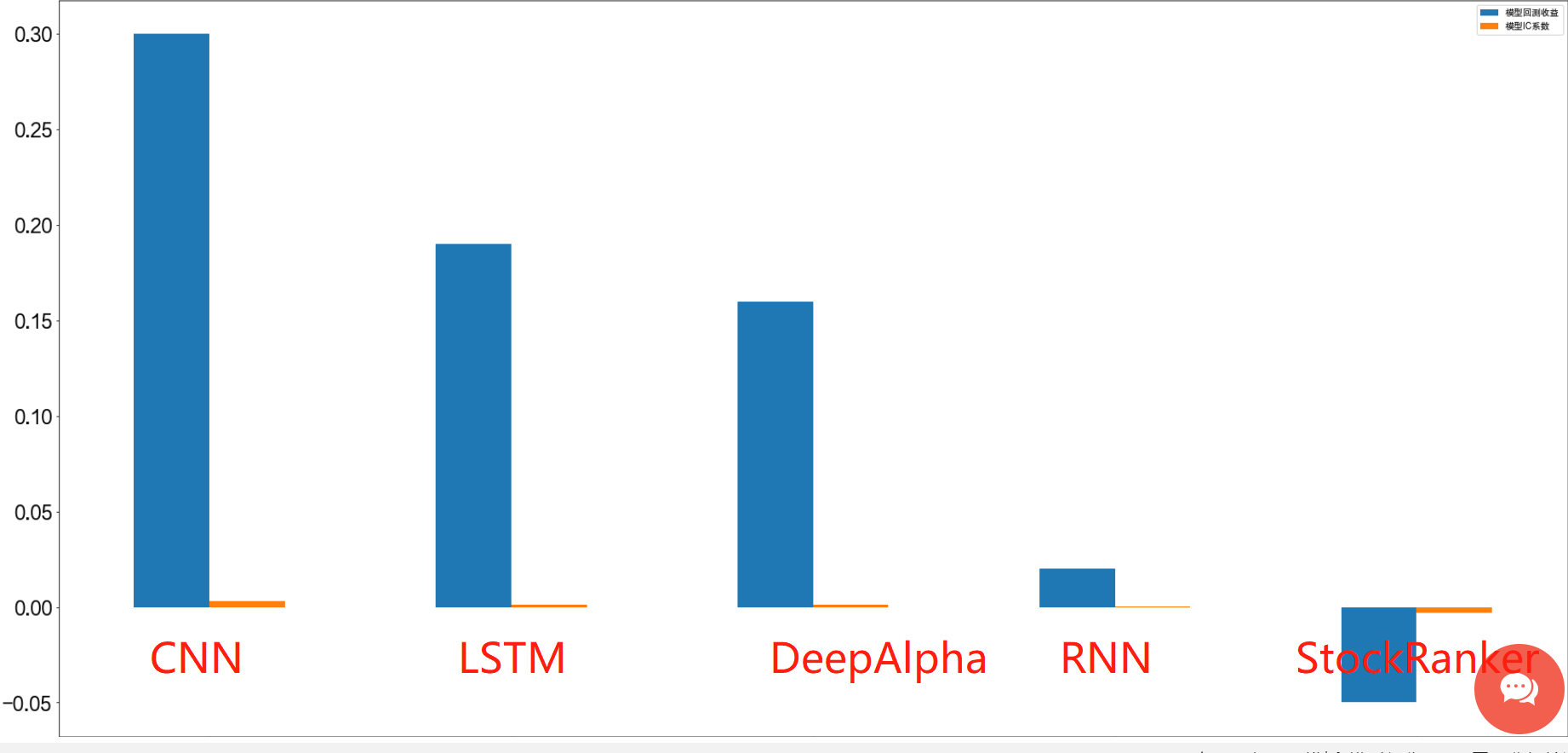
对于时间序列数据,deepalpha 对比跟LSTM,以及RNN递归网络,CNN卷积网络表现差距并不是特别明显。笔者 观察到在同类型数据(18年-21年),以及相同参数下,对比了所有算法的表现。 研究对比发现,在相同基准线下, CNN网络可能在局部表现会优于 deepalpha的绩效。模型拟合能力 CNN> LSTM>=deepalpha>RNN
 易用性和可解释性
易用性和可解释性
神经网络 最大的诟病 应该就是 可解释性不强,而且调参非常麻烦。 许多有经验的算法工程师 都将deepalpha 的结果戏称为玄学炼丹,细节都是魔鬼。对此,我深有同感。 原有的deepalpha模板中只是用了比较简单的架构和几层全连接层。 简单网络这个还是比较方便调整的,一般我们的操作流程也是从简单的模型开始调整,确认稳定之后再逐步增加网络宽度。 令人头大的是,一些中间层处理的环节,可能会让初学者难以下手。 ①首先,一些细节处理上的函数选择,以及正则化的表达上,缺乏相关文档的注解,外人不清楚在何处进行修改和调整,持续优化难以进行。
②其次,在数据标准化 和填充结构单元这里会发现,有部分因子的数据 其实做了标准化之后,是难以区分的。 比如一些比较复杂的因子,product(std(return_3, 10), constant(constant(1)))
③再来,是缺失数据填充 用0来填充,似乎效果不如用均值或者中位数。
(PS: 在标准化之后 会发现 使用数据过滤模块,会出现出现column列 无法读取的error错误,难以像stockranker模型一样简单的使用因子表达式去过滤我们的因子参数。) 比如:我希望通过特征列表表达式: cond1=(close_0-open_0)/open_0>0.03 过滤出当天阳线实体>3%的股票数据 标准化之后,就会出现列找不到。

 总结
总结
综合上述研究可以看出,deepalpha还有很大的提升空间。
优点
1.不容易过拟合,可以容纳更多的数据
2.可扩展性,数据挖掘能力,相同因子的情况下,deepalpha具备更高的上升空间
缺点
1.可解释性不强,没有办法评估中间层学习的效果
2.易用性 和便捷性并不能很好的让非专业人员很好的理解模型的构造,以及方便的调整。
展望和猜想
deepalpha在广域数据上有更好的表现,但是在低信噪比的环境表现不佳。也许结合CNN卷积层对deepalpha进行stacking堆栈,集成后的deepalpha在金融市场的泛化效果可能会更好。
\