机器学习模型
机器学习模型在金融领域中的应用已经显示出巨大的潜力和价值。这些模型通过自我学习和优化,不断提升预测精度和决策效果,从而在风险管理、投资策略、信贷评估等核心金融业务流程中,实现了更高效、更准确的自动化决策。尤其在大数据环境下,机器学习模型能够处理海量数据,揭示传统分析方法难以发现的隐藏规律和关联,为金融机构提供更加深入、全面的市场洞察和风险提示。因此,机器学习不仅优化了金融服务的运行效率和响应速度,更为个性化金融产品和服务的创新提供了技术支持。在未来,随着算法和计算能力的进步,机器学习模型有望成为金融智能化的核心驱动力。
【平台使用】平台的机器学习模型输出结果如何排序?
机器学习给股票排序,如果我要获得买预测前5或者预测后5的的股票,该怎么写代码。 如上图,我用了图形化LightGBM模型,我怀疑我买错了方向,请教该怎么改平台默认的代码?
更新时间:2025-02-16 01:19
【其他】stockranker是否能用01变量做特征?
比如 PE>0这种变量
更新时间:2025-02-15 14:36
997篇-历史最全生成对抗网络(GAN)论文串烧
什么是GAN?(本文内容整理自网络)
GAN(Generative Adversarial Netwo,生成对抗网络)是用于无监督学习的机器学习模型,由Ian Goodfellow等人在2014年提出,由神经网络构成判别器和生成器构成,通过一种互相竞争的机制组成的一种学习框架。
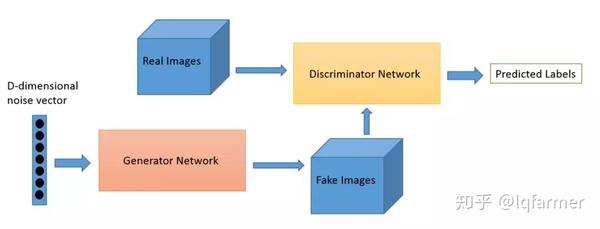 卷积神经网络之父-Yann LeCun这样评论GAN
卷积神经网络之父-Yann LeCun这样评论GAN
*在我看来,最重要的是对抗训练( GAN也称为生成对抗网络)。这一想法最初
更新时间:2024-06-12 06:04
超参寻优使用简介
导语
在机器学习模型建立过程中通常需要对模型中的超参数进行优化,本文给大家介绍超参优化模块,它可以帮助大家对我们平台上的机器学习模型进行超参数优化,让你的收益更上一层楼
超参寻优理论简介
在机器学习里,我们本质上是对损失函数进行最优化的过程。过程类似下面的曲面,算法试图去寻找损失曲面的全局最小值,当然损失曲面实际中不一定是凸曲面, 可能会更加凹凸不平,存在多个局部高低点。
我们还是回到主题,讲述的重点在于超参数
更新时间:2024-06-12 05:52
抓龙头股的机器学习模型
更新
本文内容对应旧版平台与旧版资源,其内容不再适合最新版平台,请查看新版平台的使用说明
新版量化开发IDE(AIStudio):
https://bigquant.com/wiki/doc/aistudio-aiide-NzAjgKapzW
新版模版策略:
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
新版数据平
更新时间:2024-05-17 02:36
【历史文档】高阶技巧-基于因子分组的快速回测
更新
本文内容对应旧版平台与旧版资源,其内容不再适合最新版平台,请查看新版平台的使用说明
新版量化开发IDE(AIStudio):
https://bigquant.com/wiki/doc/aistudio-aiide-NzAjgKapzW
新版模版策略:
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
新版数据平
更新时间:2024-05-16 03:28
【历史文档】策略示例-使用BigQuant平台复现XGBoost算法
更新
本文内容对应旧版平台与旧版资源,其内容不再适合最新版平台,请查看新版平台的使用说明
新版量化开发IDE(AIStudio):
https://bigquant.com/wiki/doc/aistudio-aiide-NzAjgKapzW
新版模版策略:
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
新版数据平
更新时间:2024-05-16 01:59
单因子分析
导语
了解了因子、标注和机器学习模型算法的基本知识后,面临的就是如何开发好的策略。寻找的因子是建立策略的基础,通过组合多个有效因子可以构建比较好的策略。本文主要介绍单因子分析模块的使用,通过该模块可以帮助大家检测评判单个因子的质量,为策略构建夯实基础。
因子、风险与阿尔法
因子的本质是一个信息流,也可以看做一个数学表达式,数据的变化反应并包含了投资信息,同时也代表了一个投资模式。
例如:收盘价close这个因子表达式,背后的假设就是股价越高未来收益越大,以此因子构建组合的权重比例其实就是定期轮仓购买高价股的投资模式/策略。
通常而言那些能够持续产生超额收益的因子或
更新时间:2024-05-15 02:10
AI模型评价
导语
在机器学习模型构建过程中,我们通常需要评价模型在训练集和验证集上的表现来判断模型的质量好坏,本文主要以随机森林模型为例介绍新增模型评价功能。
评价回归模型
我们以随机森林-回归模型为例,首先建立如下的模型训练可视化流程
如图所示,
- 通过证券代码列表模块m1指定了抽取数据为2010-01-01至2013-01-01的A股数据
- 通过自动标注模块m2我们计算了一个机器学习的目标,这里计算股票的未来5日收益率
- 通
更新时间:2024-05-15 02:10
机器增强一致预期-东方证券-20200901
研究结论
分析师盈利预测在海外和国内都存在明显乐观偏差,本报告将尝试用线性和非线性方法定量预测乐观偏差,并修正盈利预测以期获得更准确的预测
报告采用朝阳永续数据库,经筛选每年都有七、八万个样本数据,数据充足,适合机器学习模型使用;但随着最近几年新股数量的增多,研报对A股的覆盖率在下降,过去三个月内至少有一篇研报覆盖的股票目前只有一半左
我们从研报、分析师、公司基本面、市场信息四个角度整理了27个变量用于预测分析师的乐观偏差;预测模型测试了线性的LASSO模型和非线性的GBRT模型,每个财年都用上一个财年的数据做训练
从LASSO线性分析结果看,对乐观偏差影响最大的三个因素是:股票
更新时间:2023-06-01 14:28
Alpha预测之二,机器的比拼-东方证券-20190304
研究结论
Alpha因子库的不断扩容,让投资者有处理因子共线性、增加因子信息利用效率的需求,快速发展的机器学习模型为我们提供了解决这个高维预测问题的可行方案。本报告里测试了包括Elastic Net,SVR,RandomForrest、GBRT、ANN在内的17个模型,比较其预测能力和传统线性模型的异同。
报告里把个股超额收益率的预测拆为Dispersion 和收益率横截面zscore 两部分,前者用AR(1)模型预测,后者用alpha因子作为解释变量,通过机器学习模型预测,模型训练采用单月横截面并行训练的模式。这种拆分预测的方法效果好于直接用超额收益率作为预测目标。
我
更新时间:2023-06-01 14:28
请问缺失数据填充模块如何使用,为什么一定要输入特征,不能只输入数据
请问如何用缺失数据填充模块补全A1和A2的值(补充为0),它这里提示我一定要输入特征,平台没有提供该模块的使用例子。
、支持向量机(SVM)、随机森林(RF)、极限梯度提升树(XGBoost)、深层神经网络(DNN)等5类模型。
机器学习模型介绍本报告考察的5种机器学习模型中,MLR和线性SVM属于线性分类器,但优化目标不同。RF、XGBoost和DNN属于非线性分类器。其中,RF和XGBoost是以决策树为基学习器的集成学习方法,但模型集成的方式不一样。DNN是深度学习方法。这5种模型在机器学习领域具有很强的代表性。
策略表现从实证结果来看,5种机
更新时间:2022-10-09 06:01
Two Sigma:高频数据的机器学习模型的例子
摘要
机器学习是当前金融建模、预测和决策的最先进技术。然而,实现这一潜力需要克服许多复杂的挑战。在本次演讲中,Two Sigma的Justin Sirignano——他也是牛津大学数学副教授——讨论了金融领域机器学习的机遇和挑战。Justin介绍了用于高频数据的机器学习模型的例子,并涵盖了包括训练深度学习模型来尝试预测价格波动,以及使用强化学习来尝试确定最优执行策略。我们今天先分享第一个案例,使用RNN预测股票高频价格。
正文

作者:woshisilvio
DeepAlpha 的优势
deepAlpha的延展性和可塑性。
相比同样的决策树模型还有线性分类模型,deepAlpha无疑具有更大的可扩展空间。 一般的机器学习模型 一旦出现训练数据量过大,又或者面对一些极值数据样本和极端数据差异过大的情况,模型容易陷入过拟合的状态。 模型比较依赖训练的因子特征,如果因子选择不好,会导致模型学习效果不佳,而且在后期难以通过参数去调整学习的效果。
StockRanker绩效:98个因子
![{w:100}{w:100}{w:100}{w:100}{w:100}{w:100}{w:100}
更新时间:2022-08-17 00:16
【研报分享】华泰金工林晓明团队-基于CSCV框架的回测过拟合概率——华泰人工智能系列之二十二
报告摘要
基于CSCV框架计算三组量化研究案例的回测过拟合概率
本文基于组合对称交叉验证(CSCV)框架,以三组量化研究为案例展示回测过拟合概率(PBO)的计算流程,发现两组多因子选股模型的PBO较低,择时模型的PBO较高。案例1为7种机器学习模型的多因子选股策略,指数增强组合PBO大多在15%~50%,“XGBoost表现最佳”的结论大概率不是回测过拟合。案例2为6种交叉验证方法的多因子选股策略,多空组合PBO在20%~50%,“分组时序交叉验证表现最佳”的结论大概率不是回测过拟合。案例3为双均线50ETF择时策略,PBO在50%~90%,“参数组合[11,30]和
更新时间:2022-05-05 09:17
多因子模型研究系列之十三:基于机器学习模型的因子择时框架-渤海证券-20200331
摘要
2017年以来,随着市场上量化策略的增多,许多之前十分有效的因子,如市值因子、动量因子、波动率因子等,都出现了比较明显的震荡或者失效。想要靠传统多因子模型取得超越基准的稳定收益变得越来越难。对于因子择时模型的研究需求也在持续上升。
本篇报告分为三部分:
首先,我们介绍了因子择时常用的几个指标,包括因子估值差与配对相关性等,并测试了其与因子未来收益的相关性。
然后,我们使用随机森林函数,构建因子择时模型。与大多数因子择时模型不同,我们的预测目标是因子收益的历史移动平均与实际因子收益的差距。对于收益波动较大的因子,移动平均比较难抓到因子短期的趋势。而择时模型可以在一定程
更新时间:2021-11-26 07:35
华泰人工智能系列之二十二:基于CSCV框架的回测过拟合概率-华泰证券-20190617
摘要
基于CSCV框架计算三组量化研究案例的回测过拟合概率
本文基于组合对称交叉验证(CSCV)框架,以三组量化研究为案例展示回测过拟合概率(PBO)的计算流程,发现两组多因子选股模型的PBO较低,择时模型的PBO较高。案例1为7种机器学习模型的多因子选股策略,指数增强组合PBO大多在15%~50%,“XGBoost表现最佳”的结论大概率不是回测过拟合。案例2为6种交叉验证方法的多因子选股策略,多空组合PBO在20%~50%,“分组时序交叉验证表现最佳”的结论大概率不是回测过拟合。案例3为双均线50ETF择时策略,PBO在50%~90%,“参数组合[11,30]和\
更新时间:2021-11-26 07:30
《因子选股系列研究之六十九》:机器增强一致预期
研究结论
分析师盈利预测在海外和国内都存在明显乐观偏差,本报告将尝试用线性和非线性方法定量预测乐观偏差,并修正盈利预测以期获得更准确的预测结果
报告采用朝阳永续数据库,经筛选每年都有七、八万个样本数据,数据充足,适合机器学习模型使用;但随着最近几年新股数量的增多,研报对A股的覆盖率在下降,过去三个月内至少有一篇研报覆盖的股票目前只有一半左右
我们从研报、分析师、公司基本面、市场信息四个角度整理了27个变量用于预测分析师的乐观偏差;预测模型测试了线性的LASSO模型和非线性的GBRT模型,每个财年都用上一个财年的数据做训
从LASSO线性分析结果看,对乐观偏差影响最大的三个因素是:股票当
更新时间:2021-11-22 10:54
抓龙头股的机器学习模型
发现很少人研究抓龙头的策略,写了一个模型试试看。
感觉槽点是Label 龙头股的方法,考虑的比较天真,还需要继续改进 模型是GBT regression,Label是给龙头股打分 window内分数高的具有:涨幅高,回撤小,突破的时间早。 以此为idea 做label
还有个思路,是用概念板块的龙头概念做Label,不知道龙头概念是从哪获得的,是否有隐含的未来函数。
策略案例
[https://bigquant.com/experimentshare/bee38d198ea045eaa99abdda4c4106c1](https://bigquant.com/experiment
更新时间:2021-08-28 02:40