当深度学习遇上量化交易——因子挖掘篇
由small_q创建,最终由small_q 被浏览 1098 用户
摘要
在深度学习的所有应用场景中,股价预测也无疑是其中一个异常诱人的场景。随着传统线性模型的潜力逐渐枯竭,非线性模型逐渐成为量化交易的主要探索方向,深度学习对非线性关系良好的拟合能力让其在量化交易中面临着广阔的应用前景。但与常规的回归预测任务不同的是,股价预测问题有其独特性,存在时间序列、噪声高、过拟合等问题。当前对于深度学习在股票交易中的研究主要侧重在因子挖掘、图神经网络与知识图谱、新闻与社交媒体等非结构化数据的利用、以及时序模型改进四个方面。我们会在文章中依次探讨近5年顶会上对这四个方向的研究。
本文主要介绍MSRA在KDD 2019上发表的两篇文章,这两篇文章主要关注深度学习在因子挖掘方面的应用。
- Individualized Indicator for All: Stock-wise Technical Indicator Optimization with Stock Embedding
- Investment Behaviors Can Tell What Inside: Exploring Stock Intrinsic Properties for Stock Trend Prediction
个性化指标: 基于股票嵌入的逐股技术指标优化
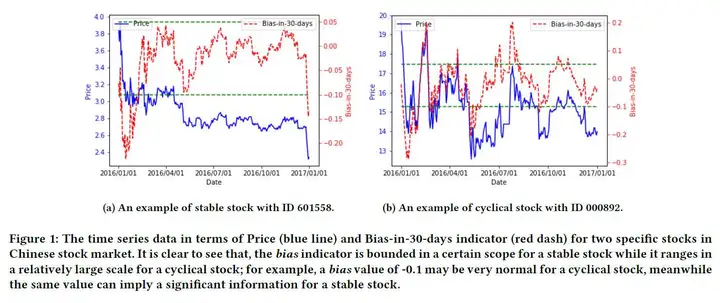
对于股票进行分析常用的手段有基本面分析(fundamental analysis)和技术面分析(technical analysis)。技术面分析依靠股票市场历史上的交易价格和成交量衍生出一系列的技术指标,成为技术因子(technical indicators)。传统的多因子模型认为同一种因子的系数(β, 因子暴露)对于所有的股票的影响是一样的。但我们稍加观察下图就会发现,对于具有不同的内禀属性(intrinsic properties)的股票,同一个因子即使在同一时间取值大致相同,对于股价的影响也是不一样的。
而要解决上述问题,需要解决下面两个问题:
- 怎么把股票分成不同种类,或者说怎么发现因子的内禀属性?
- 怎么找出不同的技术因子对不同种类股票的影响程度?即如何计算那个加权系数?
文章对上述问题分别进行了解答。
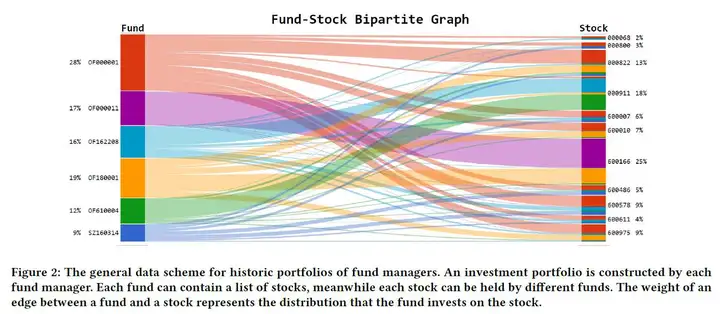
对于第一个问题,要解决它其实要给每只股票生成一个embedding,并且这个embedding要包含足够的信息。基于“万物皆可embedding”的思想,可以很自然的想到word2vec中的skip-gram和cbow两个生成embedding的方法。文章在这里采用了skip-gram的方法,但skip-gram方法建立在一个词和它周围的词组成的词组更合理的基础上,我们如何得到由有相似属性的股票组成的序列呢?文章提出了一个有意思的假设:那些专业的基金经理比起我们这些小白来姿势水平肯定不知道高到哪里去了,他们在给自己管理的基金挑选股票组合时肯定倾向于选择有相似属性的股票(但这个假设其实有两个潜在的问题,第二篇文章有提到),所以我们这些基金组合入手,生成股票序列。具体的步骤如下:
- 我们首先将股票和其所属的基金组织成一个如下图所示的二部图G=(U,V,E),其中U代表股票,V代表这些股票所述的基金,E是这两者之间的边,代表一个基金对一只股票的投资。
-
使用Random Walk算法来采样一系列的股票序列。从任意一只股票结点si开始,它到基金结点fj的概率是:
\
-
-
从基金结点fi开始到另一个股票结点sj′的概率定义如下:
因为我们只需要股票序列,在采样时去掉基金结点,只保留股票结点即可。
-
使用Skip-Gram算法对上面采样得到的股票序列进行训练可以得到股票i的embedding gi。
对于第二个问题,文章提出了一个称为TTIO(Technical Trading Indicator Optimization)的框架。其中最重要的就是通过一种称为Re-scaling Network的方法计算股票对每种技术因子的权重。它包括两步:生成初始权重和权重归一化。
因为我们的假设会让具有相似属性的股票生成相似的embedding。为了保持这种关系,我们不能进行过于复杂的变化,这里只用一个简单的线性变化来得到re-scaling score,之后使用softmax函数进行归一化:
之后使用这个这个权重乘相应的技术因子Iij获得优化过的因子Iij′:
之后使用信息系数(Information Correlation,IC)作为目标函数对这个单层神经网络进行优化。
因为投资的动态性,所以文章引入了Rotation Learning的方法随时间不断更新因子,如下图所示。

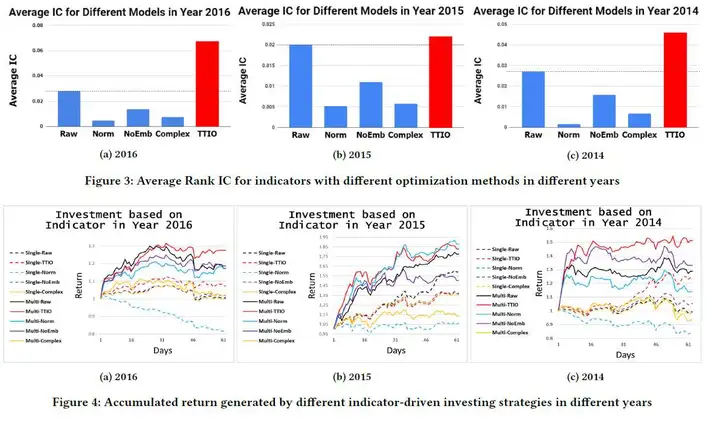
最后,文章对上述方法使用从2013年到2016年2000只股票的交易数据对如下表所示的七种因子进行了实验。对照方法包括Raw(原始因子),Norm re-scales(对原始因子进行归一化),NoEmb(将stock embedding作为训练参数直接进行训练)、Complex(将原始因子和股票embedding直接进行连接,输入一个两层的神经网络进行训练,为了测试过拟合问题)。

实验结果自然是吊打baseline,如下图所示。但也有两个其他结论值得注意,Norm方法相比Raw方法并不好,甚至要更差,这显示了除了相对大小,因子的绝对大小也很重要。而Complex虽然只使用了最简单的的两层神经网络,但过拟合问题也让它表现十分糟糕。
投资行为能看出内幕: 探索股票内在属性预测股市走势
这篇文章的出发点是虽然深度学习已经在这么多领域取得令人瞩目的成就,但在股票市场上却仍然是人类投资者占据主导地位,因为他们在做决策时会考虑股票的内禀属性,把股票分成不同的种类。所以为了达到更好的预测准确率,要向人类投资者学习,解决以下两个问题:
- 如何挖掘股票的内禀属性?
- 如何将股票静态的内禀属性融入到深度神经网络中来加强动态的股票预测?
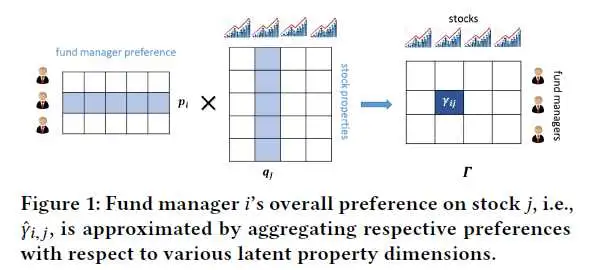
对于第一个问题,我们当然是使用skip-gram。。。额,不好意思,串文了,skip-gram是上一篇论文采取的方法,这篇文章提出了另一种解决方案,那就是万物皆可Embedding的另一个邪教——矩阵分解(Matrix Factorization)。那去哪找矩阵呢?文章提出了一个有意思的假设:那些专业的基金经理比起我们这些小白来姿势水平肯定不知道高到哪里去了,他们在给自己管理的基金挑选股票组合时肯定倾向于选择有相似属性的股票(嗯,这里没串,两篇文章其实用的是同一个假设)。所以我们构建一个M行N列的矩阵Γ,矩阵中的元素γi,j表示基金经理u对股票j的投资行为(应该是金额或者比例,文章没有写明),M和N分别表示基金经理和股票的数量。之后按下图所示的方式分解得到股票j的表示Qj,这个Qj包括qj和ujs。
分解的目标函数为:
其中pi是基金经理i的隐向量,qj是股票j的隐向量。μjs表示股票j的bias,μif表示基金经理j的bias,μ表示模型中的其他偏差。
虽然与上一篇文章生成股票embedding基于的假设相同。但是这篇文章指出了这个假设存在的问题:**除了基金经理偏好的股票属性,基金中的投资组合同样依赖于股票的动态趋势和风险分布。没有基金经理会投资一个在持续下跌的股票,即使它具有让他心动的优良属性。同样的,为了保证基金收益更加健壮,很多投资组合都会做风险平均。**但文章指出,这一问题可以通过使用足够长时间的投资组合的数据来解决,因为在长期内累积的投资行为会削弱上面两个因素的影响,让股票的内禀属性更好的暴露出来。
之后要解决的就是如何将上面得到的股票静态的内禀属性用于动态的股票预测呢?传统的做法是将股票在一个时刻的一些因子输入到类RNN的网络中,获得一个股票j在时刻t的动态表示Ztj。那么进行融合的简单想法就是直接进行拼接输入到感知机中。
但经验告诉我们,市场是动态的,它在不同的时间段对不同的股票内禀属性的偏好是不同的。所以文章提出了两种不同的方法来分别捕捉动态市场状态(dynamic market state)和和动态市场趋势(dynamic market trend)。
获取动态市场状态的方法较为简单,直接对时刻t市场上收益率最高的Kr只股票的表示向量进行平均即可获得时刻t的市场偏好St。之后利用获得的市场偏好对股票j的向量表示做内积获得这只股票的当前市场状态。
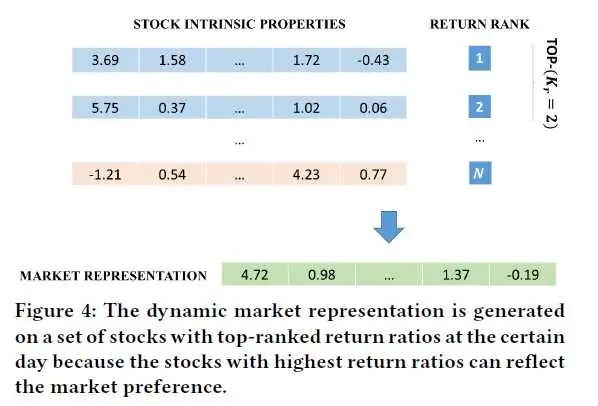
基于市场偏好在连续两天很可能是一致的假设,我们可以利用时刻t的市场状态来预测股票在t+1时刻的收益排名。
虽然市场偏好在连续两天是一致的情况很有可能发生,但它并不总是对的。并且只使用最后的市场状态可能会遭遇市场上突发的高波动。我们可以使用LSTM使用过去的市场状态预测未来的市场趋势。
之后利用S^t与股票表示Qj做内积得D^tj,与Ztj拼接输入MLP即可。
训练的损失函数包括两部分,包括回归损失和排序损失。加入排序损失是因为每个股票都是独立的。其中
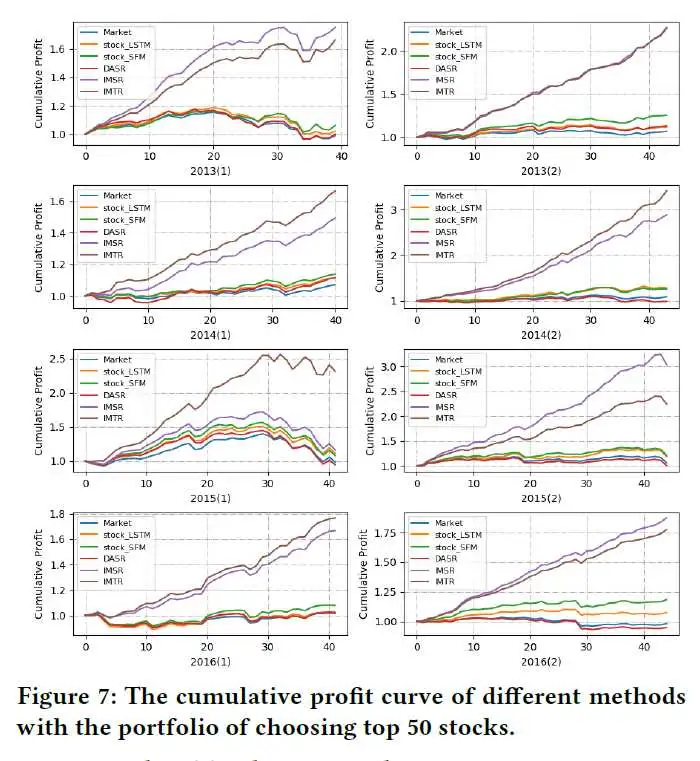
实验部分,文章采用了2012年到2016年的股市数据,用101个因子计算Ztj。对比的方法包括:stock_LSTM(ALSTM with dynamic stock inputs)、stock_SFM(A SFM with dynamic stock inputs)、DASR(Directly appending stock representation,直接拼接Ztj和Qj), IMSR(Integrating market state representations,第一种融合方法),IMTR(Integrating market trend representations,第二种融合方法)。
结果显示IMSR和IMTR优于stock_LSTM和stock_LSTM。其他的发现包括DASR因为没有考虑股票和市场的动态特性所以表现不佳,但在2015年下半年却表现不错,因为在急剧变动的市场中,股票的内禀属性是保持不变的。
总结
MSRA的两篇文章都是从传统的量化模型出发,挖掘更多的股票属性,并赋予因子动态时间特性。在将深度学习引入量化交易中的研究中,对传统的手工因子构造进行改造,发现更强大的因子或提出更有效的因子挖掘方法是可行性比较高,也是最为业界所接受的方法。