Paper Reading导读(二)
由ypyu创建,最终由qxiao 被浏览 20 用户
Instance-sensitive Fully Convolutional Networks
16年的ECCV,作者在FCN的基础上优化了FCN不能进行instance-segmentation的问题,提出了 InstanceFCN。
 Define the relative positions using k*k regular grid on a square sliding window, 使得FCN产生k*k个 score maps outputs. 这k^2个feature maps分别编码不同位置的信息,使用m/k * m/k的sliding window来分别copy每个feature map的不同位置,然后简单的 assemble 起来构成segment(resolution = m*m). 利用了图像的局部连贯性(image local coherence).
Define the relative positions using k*k regular grid on a square sliding window, 使得FCN产生k*k个 score maps outputs. 这k^2个feature maps分别编码不同位置的信息,使用m/k * m/k的sliding window来分别copy每个feature map的不同位置,然后简单的 assemble 起来构成segment(resolution = m*m). 利用了图像的局部连贯性(image local coherence).
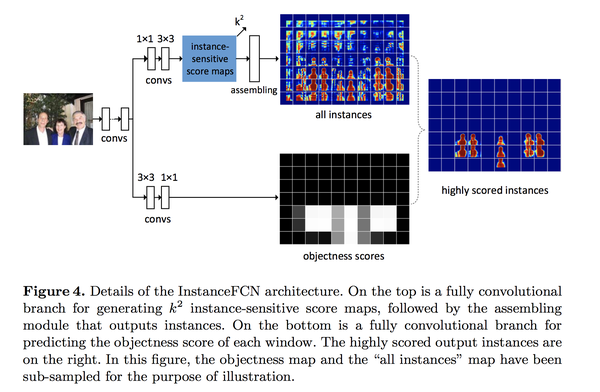 使用VGG-16来extract feature. On top of the feature map, there are two fully convolutional branches.
使用VGG-16来extract feature. On top of the feature map, there are two fully convolutional branches.
第一个分支后面接1*1 512-d conv layer来变换特征,接3*3卷积产生k*k 个sensitive score maps(k*k个feature map channels).然后使用 an assembling module is used to generate object instances in a sliding window of a resolution m×m. We use m = 21 pixels (on the feature map with a stride of 8).
第二个分支后面接3*3 512-d conv layer+1*1 conv来 per-pixel logistic regression for classifying instance/not-instance of the sliding window centered at this pixel. 分支的输出是一个objectness score map.
训练的Loss也是将两个branch结合起来构造,上面的分支用来生成mask结果,下面的分支用来判断每个mask窗口是否包含一个instance。作者也对比了10, 100, 1000个proposals下的IoU和recall.
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
 这篇文章提出了一个like-ResNet的残差连接,使用两个stream,第一个path处理full image resolution 的info(没有pooling operation), 获取精确的物体boundaries;另一个path包含一系列的pooling操作获得比较robust的features.
这篇文章提出了一个like-ResNet的残差连接,使用两个stream,第一个path处理full image resolution 的info(没有pooling operation), 获取精确的物体boundaries;另一个path包含一系列的pooling操作获得比较robust的features.
 FRRU moudle 注释
FRRU moudle 注释

Channel Pruning for Accelerating Very Deep Neural Networks
加速深度网络的一种方法,基于channel prune, 方法分为两个步骤:
1,figure out the most representative channels ,prune 冗余channels.(with a LASSO regression based method )
2. reconstruct the outputs with remaining channels with linear least squares.

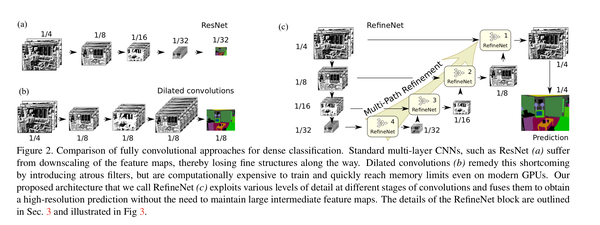
RefineNet: Multi-Path Refinement Networks for
High-Resolution Semantic Segmentation
RefineNet, a novel multi-path refinement network for semantic segmentation and object parsing. The cascaded architecture is able to effectively combine high-level semantics and low-level features to produce high-resolution segmentation maps.

Distilling the Knowledge in a Neural Network
这篇文章介绍了让大网络指导小网络的学习,从而进行模型压缩。使得小网络接近大网络的性能。
为了实现上述的知识迁移,作者提出了在训练小模型的时候,将训练目标由传统的ground truth的标签更新为所谓的soft target。soft target在训练过程中可以提供更大的信息熵,将已训练模型地知识更好地传递给新模型。
soft target获得方式如下:
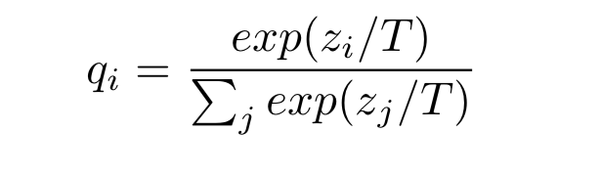 其中T为温度,控制softmax输出之前的 target的分布。
其中T为温度,控制softmax输出之前的 target的分布。
T=1时,退化成传统的softmax,T无穷大时,结果趋近于1/C,即所有类别上的概率趋近于相等。T>1时,我们就能获得soft target label。
why soft ?
举一个栗子,假如我们分三类,然后网络最后的输出是[1.0 2.0 3.0],我们可以很容易的计算出,传统的softmax(即T=1)对此进行处理后得到的概率为[0.09 0.24 0.67],而当T=4的时候,得到的概率则为[0.25 0.33 0.42]。
可以看出,当T变大的时候输出的概率分布变得平缓了,这就称之为soft。
通常我们使用softmax进行分类的时候,我们的label都是one shot label,比如我们分三类:猫、虎和猪,那么一张猫的图片它的label就是[1 0 0]。这种标注方式意味着每一类之间都是独立的,完全没有任何联系。但是事实上,猫和虎的相似度应该高于猫和猪的相似度,这种丰富的结构信息,one shot label(hard target)描述不了。此外,正因为one shot label的hard,导致了我们学习得到的概率分布也相对hard。显然对于一张猫的图片强行学习一个[1 0 0]的分布,其难度要比学一个[0.65 0.3 0.05]的分布大得多。
最后的loss也是原本的softmax hard loss + soft loss(KL distance).
传统的分类问题,模型的目标是将输入的特征映射到输出空间的一个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。
另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。然而使用teacher model的输出可以恢复出这方面的信息。具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。
**综上所述,KD的核心思想在于"打散"原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。**其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
当然KD本身还有很多局限,比如当类别少的时候效果就不太显著,对于非分类问题也不适用。