Paper Reading导读(一)
由ypyu创建,最终由qxiao 被浏览 60 用户
最近处于读论文的状态,给大家分享一些导读(一段话的论文总结),持续更新。
论文地址我就不贴了,Google一下就find得到。
主要论文涉及深度学习、计算机视觉(包括但不限于物体检测、图像分割)、模型设计及优化方面。欢迎评论区随时讨论papers,共同进步。
SENET : Squeeze-and-Excitation Networks
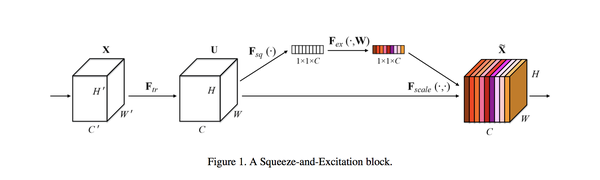
这篇文章考虑特征通道之间的关系,显著地建模特征通道之间的相互依赖关系,但又不引入新的空间维度来进行特征通道间的融合,而是采用了“特征重标定”的策略(先做全局平均池化,再接bottleneck(FC->relu->FC->Sigmoid))。使得网络有选择地增强信息量大的特征,使得后续处理可以充分利用这些特征,并对无用特征进行抑制,刷新了ImageNet top5准确率。
Xception : Deep Learning with Depthwise Separable Convolutions
 思想是通过分开独立处理cross-channel和spatial的相关性,基于CNN的特征cross-channels和feature map的空间相关性可以完全解耦这样的强假设。具体来说,extreme Inception 是先用一个统一的1*1卷积,然后连接3*3卷积(3*3卷积个数和1*1卷积输出的output channels个数一样,且每步之后都有relu),每个3*3卷积都是和1个输入channel做卷积。最后加上residual connection发现效果更好,而参数数量保持和Inception V3基本等同。
思想是通过分开独立处理cross-channel和spatial的相关性,基于CNN的特征cross-channels和feature map的空间相关性可以完全解耦这样的强假设。具体来说,extreme Inception 是先用一个统一的1*1卷积,然后连接3*3卷积(3*3卷积个数和1*1卷积输出的output channels个数一样,且每步之后都有relu),每个3*3卷积都是和1个输入channel做卷积。最后加上residual connection发现效果更好,而参数数量保持和Inception V3基本等同。
MobileNet:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
 提出深度可分离卷积,具体来说把标准卷积分为两个部分,第一步是对每个channel分别利用卷积核卷积,第二步使用1*1卷积来组合通道的输出。这种分解减少了参数量,构建轻量级的neural network,并且引入两个全局超参数(宽度factor和分辨率factor),允许使用者根据问题的约束条件,动态调整模型的大小,并且展示了mobileNet在不同视觉问题应用场景的有效性,包括细粒度分类、物体检测、人脸识别、大规模地理定位等等。
提出深度可分离卷积,具体来说把标准卷积分为两个部分,第一步是对每个channel分别利用卷积核卷积,第二步使用1*1卷积来组合通道的输出。这种分解减少了参数量,构建轻量级的neural network,并且引入两个全局超参数(宽度factor和分辨率factor),允许使用者根据问题的约束条件,动态调整模型的大小,并且展示了mobileNet在不同视觉问题应用场景的有效性,包括细粒度分类、物体检测、人脸识别、大规模地理定位等等。
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
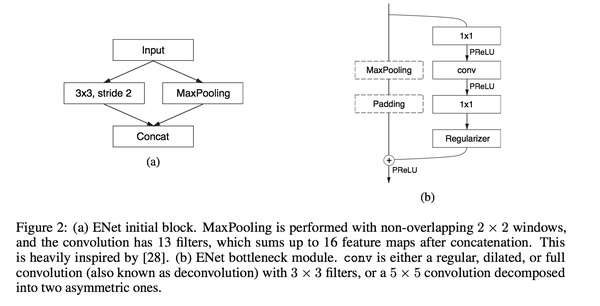 这篇文章使用SegNet作为baseline,提出了ENet这个Encoder-Decoder的网络结构。文章借鉴了很多tricks,比如dilated空洞卷积来增大感受野,使用不对称卷积来减少参数(用1*5卷积+5*1卷积来替换5*5卷积)。和SegNet不同,整个网络结构“不对称”,用一个large encoder 和 small decoder,因为对于decoder来说,作用只是在于upsample,only fine-tuning the details. 作者尝试在网络中加ReLU却得到了bad effect,后来分析原因是他们的net太小了,需要快速filter信息,最终他们采用了PRelu。最后的结果总体来说优于SegNet。
这篇文章使用SegNet作为baseline,提出了ENet这个Encoder-Decoder的网络结构。文章借鉴了很多tricks,比如dilated空洞卷积来增大感受野,使用不对称卷积来减少参数(用1*5卷积+5*1卷积来替换5*5卷积)。和SegNet不同,整个网络结构“不对称”,用一个large encoder 和 small decoder,因为对于decoder来说,作用只是在于upsample,only fine-tuning the details. 作者尝试在网络中加ReLU却得到了bad effect,后来分析原因是他们的net太小了,需要快速filter信息,最终他们采用了PRelu。最后的结果总体来说优于SegNet。
DSD: Dense-Sparse-Dense Traning For Deep Neural Networks
这篇文章介绍了DSD--- 一种将模型稀疏化,再Dense的训练方法。
DSD和dropout不一样,虽然都是在训练过程中有prune(剪枝)操作,但是DSD是有一定依据来选择(具体来说是用参数的importance)去掉哪些connections,而dropout是随机失活。另外DSD也不是模型压缩算法,DSD算法训练模型目的是提高准确率,而不是模型压缩。
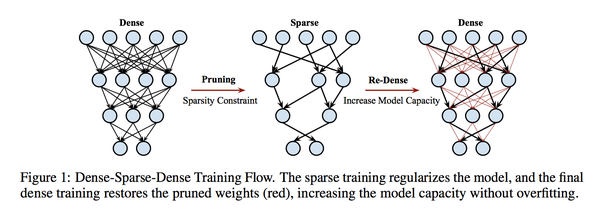 具体步骤:
具体步骤:
1.D:按照传统方式训练网络;
2.S:将除了第一层之外的所有layer(因为第一层只有三个channels)参数可视化分布,设定一个sparsity,将每一层的参数按照绝对值排序,保留top K(K = N * (1 - sparsity))绝对值大小的参数。将其余参数置为0,使其稀疏。(这里作者讨论了为什么使用绝对值,我们要使稀疏化后的Loss diff最小)。作者提出sparsity在25%到50%范围内的效果比较好。
3.D:在第二部的基础上,re-training model,学习率变为原来的1/10,然后其余不变。
最终结果:在image classification, caption generation, speech recognition上错误率都有降低。
Do Deep Nets Really Need to be Deep
文章提出了使用大模型(深度CNN)来指导浅层模型(和大模型参数差不多)来进行mimic大模型,并且达到了和深度模型几乎一样的效果。
不同的是,浅层模型使用数据的label并不是0/1这样的hard label,而是在softmax之前的输入,文章中叫“logits”. 使得浅层模型学到的是深层模型对数据函数的拟合。其他的好处,文章最后也讨论了,这样做可以排除一些错误标签的影响;student model可以学习soft labels;学习这种informative要比直接学习0/1标签更有意义。
另外,为了加速浅层模型的收敛,在data layer和隐藏层之间引入了一层linear layer(含有k个linear hidden units),表达能力不变,参数量减小,加速收敛。最后总结,For a given number of parameters, depth may make learning easily, but may not always be essential.
Deeplab-V3:Rethinking Atrous Convolution for Semantic Image Segmentation
 atrous convolution能够有效的增加filters的感受野,整合多尺度信息。文中提出了串行的cascaded ResNet blocks和并行的ASPP(Atrous Spatial Pyramid Pooling)网络,包含不同的atrous rates,采用Multigrid策略设置不同block的init rate. 对于一个实际问题,使用rate非常大的3*3 atrous 卷积,无法捕捉图像的大范围信息,退化成了1x1 filter,因为只有中心的filter权重是有效的,effectively simple degenerating 1X1 convolution,并在model的最后一层feature map上apply global average pooling,最后,论文改进了ASPP。
atrous convolution能够有效的增加filters的感受野,整合多尺度信息。文中提出了串行的cascaded ResNet blocks和并行的ASPP(Atrous Spatial Pyramid Pooling)网络,包含不同的atrous rates,采用Multigrid策略设置不同block的init rate. 对于一个实际问题,使用rate非常大的3*3 atrous 卷积,无法捕捉图像的大范围信息,退化成了1x1 filter,因为只有中心的filter权重是有效的,effectively simple degenerating 1X1 convolution,并在model的最后一层feature map上apply global average pooling,最后,论文改进了ASPP。
Pyramid Scene Parsing Network
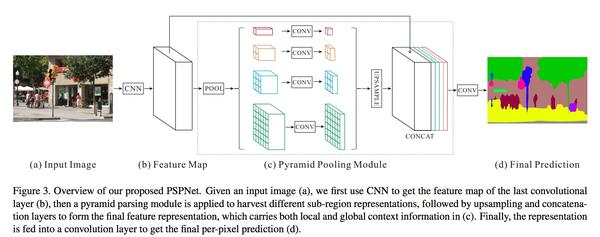 这篇文章是为了充分利用图片的上下文信息,分析了目前的FCN不同充分利用global scene category clues,在SPPNet和FCN的基础上提出了PSPNet来embed difficult scenery context features. 指出global average pooling用在了很多image segmentation场景,但是直接将他们fusion成一个vector的话会丢失空间的关系,因此使用fused information from different sub-regions。文中的卷积层全部使用dilation convolution,最后pyramid pooling融合四个不同scale的features, 然后过1*1卷积(其中使用1*1卷积做降维,整合信息),然后上采样做concate。通过实验,证实average pooling要比max pooling更work。另外网络还有一个辅助训练的Loss, 另外,使用基于OpenMPI多GPUs训练做gather 梯度信息。
这篇文章是为了充分利用图片的上下文信息,分析了目前的FCN不同充分利用global scene category clues,在SPPNet和FCN的基础上提出了PSPNet来embed difficult scenery context features. 指出global average pooling用在了很多image segmentation场景,但是直接将他们fusion成一个vector的话会丢失空间的关系,因此使用fused information from different sub-regions。文中的卷积层全部使用dilation convolution,最后pyramid pooling融合四个不同scale的features, 然后过1*1卷积(其中使用1*1卷积做降维,整合信息),然后上采样做concate。通过实验,证实average pooling要比max pooling更work。另外网络还有一个辅助训练的Loss, 另外,使用基于OpenMPI多GPUs训练做gather 梯度信息。
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
 这篇文章作者在PSPNet的基础上提出了压缩的ICNet(image cascade Net), 系统在一个GPU上达到了real-time,网络充分结合利用了低分辨率图像的语义信息和高分辨率图像的details信息, 最终在分辨率为1024*2048时,达到了30.3的fps。
这篇文章作者在PSPNet的基础上提出了压缩的ICNet(image cascade Net), 系统在一个GPU上达到了real-time,网络充分结合利用了低分辨率图像的语义信息和高分辨率图像的details信息, 最终在分辨率为1024*2048时,达到了30.3的fps。
文章开始对Time Budget进行分析,进行了downsampling input, downsampling feature, model compression(通过kernel weights的L1范数进行drop)等试验,并没有达到速度和精度均能提升的result. 于是分析得到了级联网络。
网络分为三个branch(three inputs),low resolution(1/4 scale)、median resolution(1/2 scale)、high resolution(1/1 scale), 分为进行卷积提取特征,其中downsize 均为1/8,且low branch 和 median branch share conv parameters, low branch基于FCN-based PSPNet, median branch has 19 conv layers,而High branch只有three conv layers(kernel size 3*3 and stride 2 to downsize the resolution).
提出了Cascade Label Guidance来进行优化网络.
 ICNet网络在训练时使用low-resolution input来获取主要的semantic info, 使用high-resolution来help refinement. 使用上图的cascade feature fusion(CFF)来combine 不同分辨率的feature. unit输入有三个,分别是label, feature map F1, feature map F2. 中间使用dilated conv来融合周围pixels的信息。
ICNet网络在训练时使用low-resolution input来获取主要的semantic info, 使用high-resolution来help refinement. 使用上图的cascade feature fusion(CFF)来combine 不同分辨率的feature. unit输入有三个,分别是label, feature map F1, feature map F2. 中间使用dilated conv来融合周围pixels的信息。
训练的时候使用三个loss, 分别为两个三输入的CFF unit softmax loss,一个1/4 的两输入的softmax loss, 加权训练,最后的压缩也是利用F1范数对参数进行drop.