Deep Residual Networks学习(一)
由ypyu创建,最终由qxiao 被浏览 360 用户
回顾去年的DCNN成果和深度学习发展,就必然会提及到到Kaiming He的深度残差网络 (https://arxiv.org/abs/1512.03385)。这不仅是因为ResNet一举拿到了CV下多个比赛项目的冠军,更重要的是这一结构解决了训练极深网络时的degradation问题。作为我来到MSRA第一个月重点学习的论文,现在在这里分享一下我这大半个月以来的学习成果。
论文解读
He首先提出一个问题:Is learning better networks as easy as stacking more layers?回答这个问题的一个障碍在于一个著名的问题:梯度消失/爆炸,然而这个障碍可以通过合理的初始化和其他一些技术来解决,接下来看一张图:
 这是我在论文结果复现时在CIfar10上复现的训练过程图,plain-20代表不含残差结构的纯粹的20层的网络结构,很明显可以看出随着网络深度增加,performance却在下降。He将这一现象称为degradation,亦即随着网络深度的增加,准确度饱和并且迅速减少。这一问题广泛存在于深层的网络结构中,例如VGG的论文中也观察到这一现象。degradation表明不是所有的系统都能很容易地被优化。
这是我在论文结果复现时在CIfar10上复现的训练过程图,plain-20代表不含残差结构的纯粹的20层的网络结构,很明显可以看出随着网络深度增加,performance却在下降。He将这一现象称为degradation,亦即随着网络深度的增加,准确度饱和并且迅速减少。这一问题广泛存在于深层的网络结构中,例如VGG的论文中也观察到这一现象。degradation表明不是所有的系统都能很容易地被优化。
接下来,He提出了深度残差学习的概念来解决这一问题。首先我们假设我们要求的映射是H(x),通过上面的观察我们意识到直接求得H(x)并不那么容易,所以我们转而去求H(x)的残差形式F(x)=H(x)-x,假设求F(x)的过程比H(x)要简单,这样,通过F(x)+x我们就可以达到我们的目标,简单来说就是下面这幅图,我们将这个结构称之为一个residual block。
 相信很多人都会对第二个假设有疑惑,也就是为什么F(x)比H(x)更容易求得,关于这一点,论文中也没有明确解释。但是根据后面的实验结果确实可以得到这一个结论。
相信很多人都会对第二个假设有疑惑,也就是为什么F(x)比H(x)更容易求得,关于这一点,论文中也没有明确解释。但是根据后面的实验结果确实可以得到这一个结论。
“Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks.”
这里放上Kaiming大神论文中的一句话,大家自行感受即可**...**
网络结构
接下来让我们关注一下ResNet的网络结构:
 PlainNet结构主要基于VGG修改而得到,接下来我们重点关注ResNet结构。可以发现,主要结构与PlainNet一致,只是多了许多shortCut连接,可以发现,通过shortcut,整个ResNet就可以看成是许多个residual block堆叠而成。这里值得注意的是虚线部分,虚线部分均处于维度增加部分,亦即卷积核数目倍增的过程,这时进行F(x)+x就会出现二者维度不匹配,这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
PlainNet结构主要基于VGG修改而得到,接下来我们重点关注ResNet结构。可以发现,主要结构与PlainNet一致,只是多了许多shortCut连接,可以发现,通过shortcut,整个ResNet就可以看成是许多个residual block堆叠而成。这里值得注意的是虚线部分,虚线部分均处于维度增加部分,亦即卷积核数目倍增的过程,这时进行F(x)+x就会出现二者维度不匹配,这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
A.zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
B.projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
结果复现
暂时还没有在ImageNet上复现ResNet结果,因为太耗时了喂,听师兄说152层的ResNet在ImageNet12上要跑一个月:(,等以后有时间在尝试吧。接下来的部分均是ResNet在Cifar10上的复现结果,所有的实验都是在caffe上完成的。
 依据论文中结构,所有的卷积核都是3x3的,依据上表总共是6n+2层,n代表residual block的数目。**注意:在论文中cifar10上对所有的恒等层均采用A方法,但由于caffe暂时不支持zero_padding,所以在本文中结果均采用B方法。**A方法我最终也进行了复现,但这需要向caffe中添加新层,留待下次再写吧。
依据论文中结构,所有的卷积核都是3x3的,依据上表总共是6n+2层,n代表residual block的数目。**注意:在论文中cifar10上对所有的恒等层均采用A方法,但由于caffe暂时不支持zero_padding,所以在本文中结果均采用B方法。**A方法我最终也进行了复现,但这需要向caffe中添加新层,留待下次再写吧。
数据预处理部分论文中采取对图像各边扩展4个pixels的方式,亦即将32x32图像扩展成40x40的图像,训练时再随机crop一个32x32的部分进行训练,但这里暂时没有进行这个操作,因为刚开始对CV的很多操作还不是很熟悉,所以采取了原始的32x32的图像截取28x28图像的方式。
接下来就是一些训练参数的设置了,如下:
weight_decay=0.0001momentum=0.9batch_size=100learning_rate=0.1,0.01/40k,0.001/80kmax_iter=100k
接下来就是实验的结果图了:
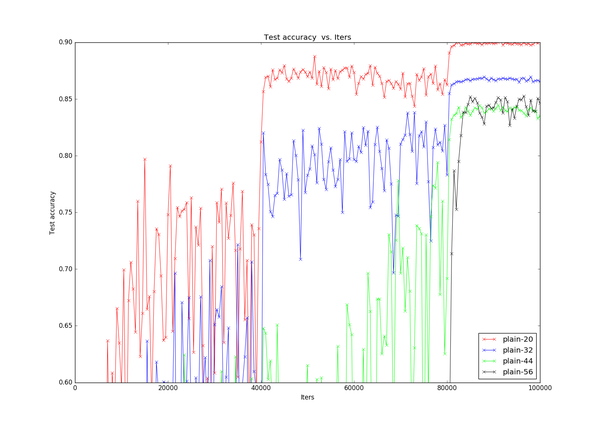 首先是PlainNet,下面一张是限制y轴取值后得到的细节图片,很明显可以看出degradation问题:随着网络层数的增加,accuracy不增反降
首先是PlainNet,下面一张是限制y轴取值后得到的细节图片,很明显可以看出degradation问题:随着网络层数的增加,accuracy不增反降

 接下来就是万众瞩目的ResNet了,上面的那张图可能不太清楚,可以看一下下面的细节图,这时候可以明显看出residual block的威力了,解决了degradation的问题,这样我们可以充分享受深度深度带来的perfomance的提升!下面放一张我前期所有实验所得到的结果表:
接下来就是万众瞩目的ResNet了,上面的那张图可能不太清楚,可以看一下下面的细节图,这时候可以明显看出residual block的威力了,解决了degradation的问题,这样我们可以充分享受深度深度带来的perfomance的提升!下面放一张我前期所有实验所得到的结果表:

PlainNet明显显现出degradation的问题,下面我们重点看ResNet,这里我实验了三种初始化方法,第一种是均值为0,标准差为0.01的高斯分布,第二种是论文中所使用的初始化方法,亦即msra方法(https://arxiv.org/abs/1502.01852),第三种就是xavier了,可以看出:1.对三种初始化方法,随着深度增加,accuracy均得到提升2.msra的初始化方法能达到最佳甚至超过论文中的结果
分析与后续
一.首先是前面提到的,在这里的复现并没有使用pixel padding的数据增强方法,却达到了接近甚至超过论文中结果的performance,难道是源于我们在恒等层使用了B方法而论文中使用了A方法吗?答案是yes,后续会有进一步分析验证。
二.网络结构中采用了batch normalization,这个层的作用是什么?从上述可以看出,msra初始化方法要由于其他两种,为什么?这些都会在后续给出分析
三.后面还将给出另一篇文章的解读(https://arxiv.org/abs/1603.05027),实验其中的pre-activation和bottleneck结构
四.由于caffe结构限制,即使采用了多GPU,最终也只实验到164层的网络,对于上千层的网络则实在是没办法跑起来,希望有成功复现的人能给一点建议,感激不尽!
\