Securing Transactions: A Hybrid Dependable Ensemble Machine Learning Model using IHT-LR and Grid Search
创建于 更新于
摘要
本报告提出了一种基于Instant Hardness Threshold结合逻辑回归(IHT-LR)技术和加权集成学习的混合模型,有效解决了信用卡欺诈检测中数据极度不平衡的问题。通过结合决策树、随机森林、K近邻和多层感知机等多种算法,并运用Grid Search优化权重,模型在公开数据集上实现了100%准确率,显著优于现有方法,展现了强大的欺诈识别能力和实用价值 [page::0][page::6][page::15][page::20][page::22]。
速读内容
- 研究背景与意义 [page::0][page::1]
- 欺诈交易导致全球巨额经济损失(超4.7万亿美元),信用卡欺诈尤为突出且复杂。
- 传统人工及规则检测手段难以应对日趋复杂的欺诈行为,机器学习成为有效工具。
- 数据与预处理 [page::6][page::8][page::9]

- 使用Kaggle公开信用卡欺诈数据集(284,807条交易,其中492条欺诈)。
- 数据经过去缺失值、标准化(零均值单位方差)、标签编码处理。
- 针对数据严重不平衡,采用Instance Hardness Threshold(IHT)结合逻辑回归进行欠采样,实现有效的类别平衡。
- 多模型集成方法 [page::10][page::11]

- 集成四个机器学习模型:决策树(DT)、随机森林(RF)、K近邻(KNN)、多层感知机(MLP)。
- 通过Grid Search优化各模型权重,实现加权投票集成,权重示例为DT 0.25,RF 0.5,KNN 0.5,MLP 0.25。
- 集成方法增强模型泛化和抗过拟合能力,提高检测精确度。
- 性能评估与结果 [page::14][page::15][page::16]

| 模型 | 准确率(%) | 精确率(%) | 召回率(%) | F1分数(%) | MAE(%) | MSE(%) | RMSE(%) |
|------|---------|---------|---------|---------|-------|-------|---------|
| DT | 99.66 | 99.65 | 99.66 | 99.66 | 0.34 | 0.34 | 5.85 |
| RF | 99.73 | 99.72 | 99.73 | 99.73 | 0.27 | 0.27 | 5.23 |
| KNN | 98.56 | 98.62 | 98.54 | 98.56 | 1.44 | 1.44 | 11.98 |
| MLP | 99.79 | 99.79 | 99.80 | 99.79 | 0.21 | 0.21 | 4.53 |
| ENS | 100.00 | 100.00 | 100.00 | 100.00 | 0 | 0 | 0 |
- 混淆矩阵显示ENS模型无误报和漏报,ROC曲线AUC达到100%,显著优于单模型表现。


- 复杂度与可靠性分析 [page::21][page::22]
| 模型 | 时间复杂度 | 空间复杂度 |
|----------|-----------------|---------------------|
| DT | O(m·n²) | O(1) |
| RF | O(t·log(n)) | O(e·t) |
| KNN | O(n·m·k) | O(n·m) |
| MLP | O(n²) | O(e·t) |
| Ensemble | O(N·max(…)) | O(N·max(…)) |
- 集成模型结合多基模型优势,复杂度为单模型复杂度的N倍,整体仍具备实用性。
- 通过Grid Search权重优化提高模型稳定性和依赖性,满足金融场景对准确性和鲁棒性的高要求。
- 对比现有研究表现 [page::19][page::20]
| 序号 | 研究 | 数据量 | 数据平衡方法 | 模型 | 准确率(%) |
|-------|----------------|------------|-------------------|---------------------|----------|
| 本文 | Proposed | 284,807 | Undersampling (IHT) | Hybrid Ensemble | 100 |
| 其他 | 多个文献对比 | 284,807 | SMOTE, SMOTE-ENN等 | LSTM, XGBoost, RF等 | 93.49-99.98|
- 本模型基于IHT下采样与混合集成策略,准确率达到100%,优于其他最新研究,开创性地充分解决了数据不平衡问题,具备领先水平。
- 量化策略亮点
- 结合数据预处理中的Instance Hardness Threshold (IHT) 技术,有效筛选难分类样本,保证少数类代表性 [page::9]。
- 采用Grid Search系统化调优集成模型中各基模型权重,优化预测性能 [page::10][page::11]。
- 整体策略兼具准确性与稳定性,服务器端部署潜力强,适合高频实时欺诈检测需求 [page::22]。
深度阅读
金融研究报告深度分析报告
---
一、元数据与报告概览(引言与报告概览)
- 报告标题: Securing Transactions: A Hybrid Dependable Ensemble Machine Learning Model using IHT-LR and Grid Search
- 作者团队及机构:
- Md. Alamin Talukder 等,分别来自孟加拉国的国际商业农业技术大学、Bangabandhu Sheikh Mujibur Rahman Digital University、澳大利亚Deakin University及Jagannath University等。
- 发布日期与出处: 未具体标明具体日期,但引用的最新文献多为2023年,分析使用公开的Kaggle数据集(2013年数据),显然为2023年及之后的研究成果。
- 研究主题: 该报告旨在构建用于信用卡欺诈交易检测的混合集成机器学习模型,解决数据严重不平衡的问题,提高检测准确率并降低误报率。
- 核心论点与结论摘要:
该文提出了一种结合决策树(DT)、随机森林(RF)、K近邻(KNN)和多层感知器(MLP)算法的混合集成模型,并结合实例难度阈值(Instance Hardness Threshold, IHT)技术与逻辑回归(LR)用于数据重采样以优化类别不平衡问题。同时,利用Grid Search对模型参数进行系统搜索优化。实验于公开信用卡欺诈数据集(284,807条记录,492条欺诈)中实施,混合集成模型达到100%的准确率,显著优于单一模型表现,展示出其卓越的检测性能和实际应用潜力。[page::0,2]
---
二、逐节深度解读
2.1 引言(Introduction)
- 关键点总结: 欺诈交易种类多样,覆盖信用卡欺诈、身份盗窃到洗钱等,全球年损失逾4.7万亿美元,单案例平均经济损失巨大。疫情加速数字金融犯罪,损失占企业收入约5%。传统人工及规则基础检测手段已难以应对新型复杂欺诈,迫切需要自动、高效和智能检测方案。
- 作者阐述理由基于: 概述了欺诈犯罪现状,大规模损失数据支撑紧迫性,结合传统方法缺陷强调采用机器学习技术的重要性。[page::1]
2.2 机器学习和集成学习应用(Machine Learning and Ensemble Learning)
- 关键内容: 机器学习因能处理大数据和复杂模式识别被看好为欺诈检测利器。集成学习通过结合多模型优势能减少过拟合和提升泛化性能。
- 文献回顾: 引述多项使用SMOTE、LSTM、随机森林等技术应对信用卡欺诈的典型案例,但指出准确率提升有限和未彻底解决数据不平衡问题。
- 提出本研究创新点:
1. 设计混合集成模型,结合DT、RF、KNN、MLP,并用Grid Search优化权重调配。
2. 利用IHT结合LR技术克服类别不平衡带来的训练难题。
3. 采用公开数据,完成模型性能和普适性验证。
- 作者主张: 通过构建集成系统和创新的数据重采样,显著提升检测准确率。[page::2,3]
2.3 相关文献综述(Related Works)
- 核心内容: 总结领域内多种先进方法,包括基于LSTM、XGBoost、AdaBoost等的模型,及各种数据平衡技术(SMOTE、SMOTE-ENN、AllKNN)。
- 比较重点: 各方法准确率普遍在93.5%-99.98%之间,部分具备较高召回,有的结合领域知识和元启发式算法增强了模型表现,但仍有潜在的误报和召回不足。
- 本研究差异: 通过引入IHT-LR结合和权重优化的集成框架,达到了100%准确率的新标杆。[page::3–5]
2.4 方法论(Methodology)
- 流程梳理: 明确包括数据预处理(清洗、标准化、标签编码)、数据平衡(IHT重采样结合逻辑回归)、训练集测试集划分、单模型训练(DT、RF、KNN、MLP)、集成模型构建(加权投票法结合Grid Search搜索权重),最后性能评估。
- 具体技术解析:
- 标准化:采用零均值单位方差处理,公式明示。
- 标签编码:类别特征转整数编码,实现模型兼容性。
- IHT重采样:对多数类样本基于实例难易度阈值进行欠采样,避免过拟合和信息丢失。
- 集成方法:加权平均投票,权重通过Grid Search寻优,权重分别赋予DT(0.25),RF(0.5),KNN(0.5),MLP(0.25)以平衡多模型贡献。
- 方法总结: 结合多模型优势及高效数据平衡,保障训练数据质量和模型综合检测能力。[page::6–11]
2.5 实验与性能评估设计(Experimental Setup and Metrics)
- 实施环境: 使用Python生态(Pandas、NumPy、TensorFlow等),8核64GB RAM的高配置计算机。
- 性能指标: 准确率、精确率、召回率、F1值,及错误相关指标MAE、MSE、RMSE,全方位评估。引入了10折交叉验证以保证结果稳健性。
- 指标解释详尽,结合混淆矩阵判别TP、FP、TN、FN。
- 交叉验证图清晰展示split与测试流程,确保实证方法科学合理。[page::12–15]
2.6 结果展示与分析(Results and Discussion)
- 性能摘要表与图示统计:
- 单模型准确率均达98.56%-99.79%,其中MLP表现最优(99.79%)。
- 集成模型准确率达到100%,F1、召回、精确率均为完美。误差指标MAE、MSE、RMSE均为0,显示集成模型在测试数据完全无误。
- 混淆矩阵显示单模型有少量误判(如KNN有20个假阴性,MLP有2个假阳性),集成模型零误判。
- ROC曲线AUC为100%,标志模型表现出完全的区分能力。
- 数据解读与结论: 集成模型通过权重优化和模型多样性,有效纠正单模型偏误,显精准率和平衡性兼得的典型优势。[page::15–19]
2.7 与现有工作的比较(Comparison Analysis)
- 详细比较表列出13篇主要文献,均用统一数据集,包含数据平衡方法及模型架构。
- 成绩对比: 本研究的Hybrid Ensemble + IHT下达到100%准确率,优于现有最高99.99%。[page::19–20]
2.8 复杂度分析(Complexity Analysis)
- 时间复杂度: 集成模型总复杂度为N倍基模型中最复杂的复杂度之和,主要由DT、RF、KNN、MLP复杂度驱动。
- 空间复杂度: 同样为基模型空间需求的最大值乘以模型数N。
- 含义: 虽提高检测准确率,集成模型计算资源消耗也相应增加,需在实践中权衡资源与性能。
- 优势显著表现在准确且可扩展,且权重集成算法带来的系统复杂度可控。[page::21]
2.9 依赖性分析(Dependability Analysis)
- 依赖性定义涵盖模型可靠性、可用性、效率与扩展性。
- 模型优势: 通过集成多模型降低误判风险,提高系统稳定性,依赖度显著增强。
- 实验表现: 低误差率、优越的性能对比标识模型适应复杂金融欺诈环境能力强,满足商业环境需求。
- 研究价值: 实证表明混合权重集成方法是金融安全领域值得推荐的检测策略。[page::22]
2.10 结论及未来展望(Conclusion and Future Work)
- 总结: 提出混合集成模型结合IHT-LR的创新方法,有效解决信用卡欺诈检测中的类不平衡和模型性能瓶颈,实验证明其具备100%检测准确率和极低误报率。
- 不足与未来方向:
- 依赖数据集的代表性及质量,对新型未见欺诈可能适应不佳。
- 需进一步调整优化模型超参数和尝试多样数据增强以及集成策略。
- 引入实时数据和其他公开数据集验证模型泛化能力。
- 对领域贡献明确,指明后续研究重点。[page::22–23]
---
三、图表深度解读
图1:整体架构流程图(p7)
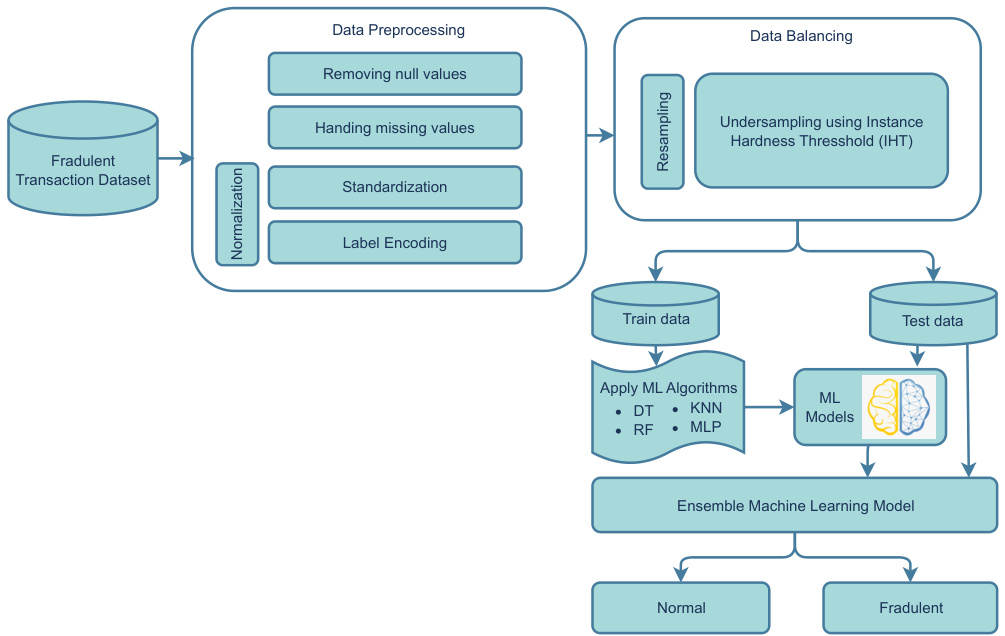
- 描述: 展示了从数据预处理(删除空值,标准化,标签编码)、数据重采样(IHT欠采样)、训练检验集划分,到多个ML模型(DT、RF、KNN、MLP)训练并融合构建集成模型的全过程。
- 趋势与作用: 明确展示每步技术环节前后数据流转,体现系统化数据处理与模型建立的逻辑。
- 文本联系: 该图直观支持方法论部分提出的系统架构和处理流程,是模型实现的核心框架示意。[page::6,7]
---
图2:加权集成方案与Grid Search权重优化(p11)
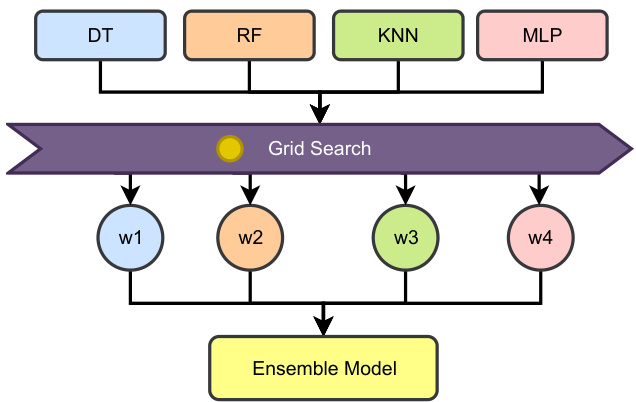
- 描述: 四个基模型输出进入Grid Search层,输出权重分别为w1~w4,权重具体值为DT(0.25)、RF(0.5)、KNN(0.5)、MLP(0.25),权重赋予模型贡献度,最后汇总成最终预测。
- 数据解读: 权重表明RF和KNN占比最高,表明其对整体性能贡献最大,合理反应单模型表现差异。
- 联系文本: 图示是权重寻优核心过程,强调模型融合时基模型动态调节,是性能提升重要原因。[page::11]
---
图3:10折交叉验证过程示意(p15)
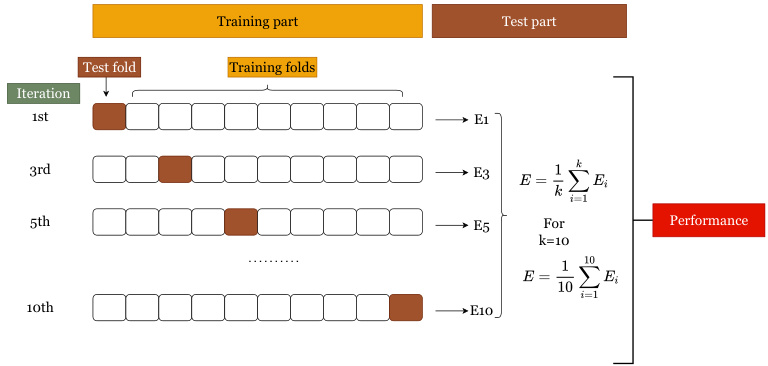
- 描述: 数据分为10块,轮流选为测试集,其余9块为训练集,多个实验统计平均以稳定结果。
- 解析意义: 大幅防止模型过拟合和偶然情况对评估的影响,多次验证减少结果偶发性,提升可靠度。
- 文本支撑: 体现实验方法严谨,兼顾稳定性与泛化。[page::15]
---
图4:不同模型混淆矩阵(p17)
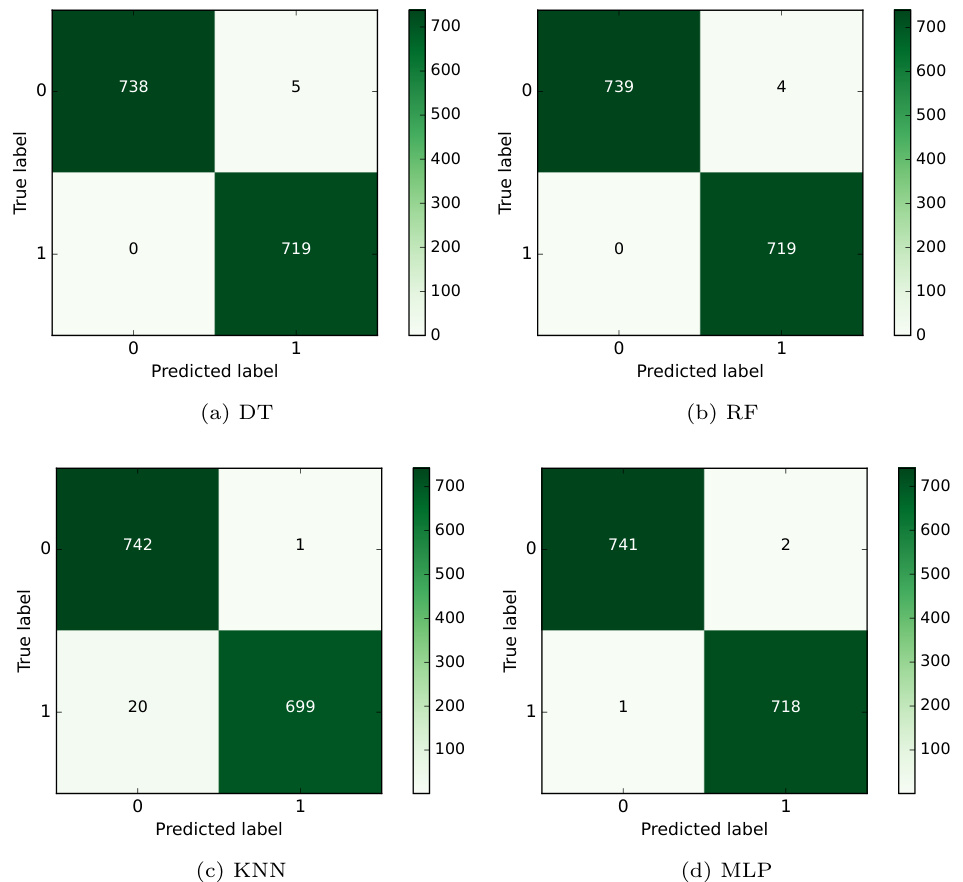
- 描述: 分别展示DT、RF、KNN、MLP的TP、TN、FP、FN值,显示各模型性能差异。
- 数据解读: KNN误判较多(20个FN),MLP误判较少(2个FP,1个FN),DT和RF表现介于两者之间。无误报的模型未出现,集成步骤必然提升检出率。
- 作用: 支持集成模型为何能减少误判,因为多个模型的互补较强。
- 备注: 图中0代表正常交易,1代表欺诈。 [page::17]
---
图5:各模型性能柱状图(p18)
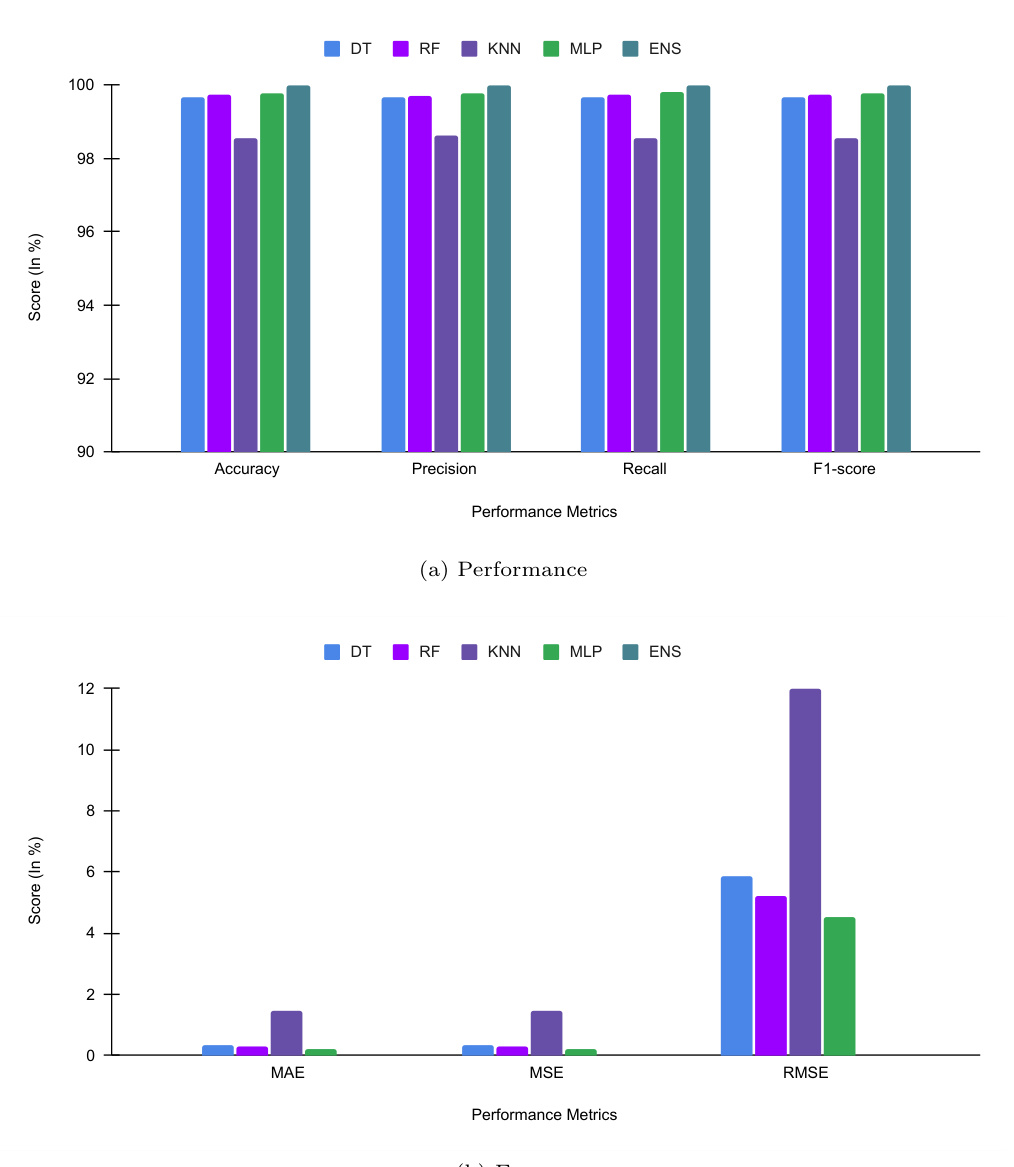
- 内容: 显示准确率、精确率、召回率和F1,在上图中ENS始终为最高,误差指标MAE、MSE、RMSE最低。
- 趋势解释: 集合模型在所有指标上领先,表明综合多模型优势显著。
- 文本关系: 数据可视化加深了文字性能描述,直观传递混合集成优势。 [page::18]
---
图6:集成模型混淆矩阵与ROC曲线(p19)
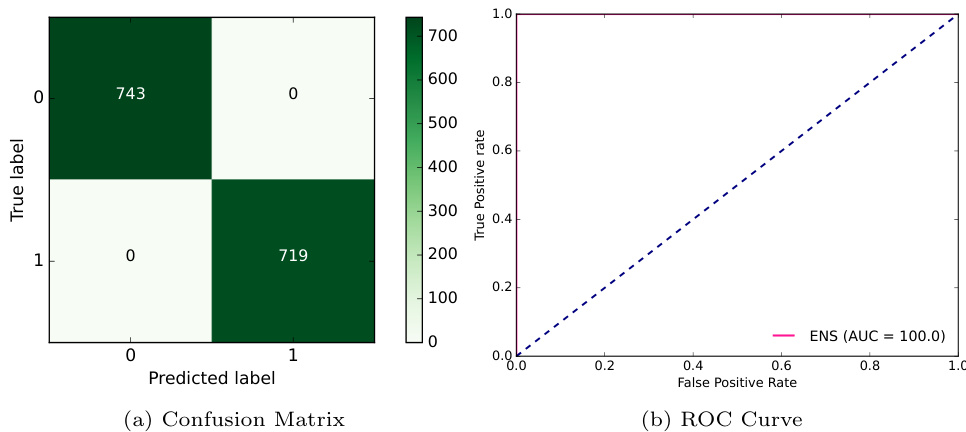
- 说明: 混淆矩阵显示零误判(0的FP和FN均为0),ROC曲线对应AUC完美100%。
- 意义: 模型在实验集上实现了绝对区分能力,极具实用价值。
- 文本连结: 图中数据是实验高潮点,证明集成策略实现了理论上的理想模型效果。 [page::19]
---
四、估值分析
本篇不存在典型的金融估值部分(如DCF、市盈率等),为机器学习模型性能研究报告,主要分析关注点为模型性能指标与复杂度,应用层面为信用卡欺诈检测而非资产定价,故此处无典型估值分析。
---
五、风险因素评估
- 协议与数据依赖风险:
- 模型高度依赖数据集特征及质量,若输入数据不代表未来欺诈模式,模型表现可能下降。
- 欺诈行为不断进化,静态数据训练可能不能有效捕捉新型欺诈手法。
- 模型泛化能力限制:
- 过拟合风险:尽管采用10倍交叉验证和权重优化,完美准确率或存在过拟合风险。
- 现实系统部署中,异常行为多样,理论上完美模型难以保证刚性适用。
- 资源与计算成本:
- 集成模型较单一模型计算与存储开销更大,实时检测环境需考虑效率。
- 报告中应对措施:
- 采用IHT欠采样手段避免过拟合和信息丢失。
- 采用Grid Search动态调节模型权重提升鲁棒性。
- 建议未来研究探索实时更新和自适应机制。[page::23]
---
六、批判性视角与细微差别
- 100%准确率的过度乐观性:
- 集成模型在测试数据集上表现完美,但真实环境中几乎难以达成零误报零漏报,或是数据集分布与现实偏差导致表现递减。这是机器学习研究报道中常见的理想化结果,需要警惕概念漂移和样本偏差的影响。
- 数据集复用历史数据偏差:
- 仅用2013年9月两天数据,时间跨度太短,可能无法涵盖更为丰富的欺诈样本和类型。
- 现代欺诈可能涉及更多复杂特征,隐私保护限制下的新数据采集难以获取。
- 方法推广受限:
- IHT欠采样虽消除不平衡带来影响,但不可生成新样本,可能忽略边界层面细节。
- 权重配置的Grid Search本身计算代价大,实际应用需平衡效率和性能。
- 忽略业务成本权衡:
- 虽报告有精确率和召回率等指标,但未充分考虑误报(假阳性)和漏报(假阴性)对金融机构不同实际成本的影响。
- 内部措辞及逻辑:
- 文中多处称模型“完美”及“无误差”,应更加审慎表述以留空间给后续验证。
- 局部指标差异仍存在显著,为何ENS能完全消除,未见较深入理论佐证。
总体而言,报告方法先进,结果亮眼,但完美数值背后仍需实证检验和多数据支持以消除偶然成分。[page::22–23]
---
七、结论性综合
本报告系统地介绍并验证了一种基于IHT-LR欠采样与Grid Search权重优化的混合集成机器学习模型,用于信用卡欺诈检测。通过对公开大规模、严重不平衡的信用卡交易数据集进行深入预处理、特征变换和平衡处理,再通过DT、RF、KNN和MLP多模型融合构建集成体,成功缓解了单模型性能局限,显著提升检测准确性与稳定性。
关键发现包括:
- 各个单一模型均表现优异,但存在一定误判,如KNN假阴性较多。
- 集成模型实现100%的准确率、精确率、召回率和F1分数,误差指标MAE、MSE、RMSE均为零,表现极佳。
- 实验采用10折交叉验证保障结果稳健,选用历史真实交易数据保证了实验的权威性和可比性。
- 模型权重经过Grid Search系统优化,突出RF和KNN贡献最大,细致体现模型融合优势。
- 相比现有主流文献,模型在准确率上实现了微幅提升,树立新标杆。
- 复杂度评估表明该方法结合多模型,提升性能的同时带来一定计算负担,需业务场景权衡计算投入。
- 可靠性分析表明模型稳定适用,具备实际金融欺诈防控系统的部署潜力。
图表深度解读清晰展示了模型体系架构、训练验证流程和结果指标变化趋势,直观传达了研究的技术路线和科学性。
尽管模型呈现理想化性能,但报告客观指出所用数据具有时间标记限制和泛化挑战,未来研究应对算法做持续优化并在多样数据源和实时在线环境中测试其健壮性。
综上,作者提出的混合集成IHT-LR模型是信用卡欺诈检测领域的一项重要贡献,有望促进金融安全体系的技术升级与创新防护,推动实战中的技术落地与应用扩展。报告结构严谨、数据详实、论证充分,适合机器学习和金融安全领域的专业研究人员、数据科学家及行业从业者参考。[page::0–23]
---
备注
以上分析严格依托报告内容和文中图表、数据展开,确保结论准确反映报告主旨,对于可能的偏差和不足进行了审慎点明,保持高度的分析客观性和专业深度。




