利用 gplearn 进行特征工程
由small_q创建,最终由small_q 被浏览 1050 用户
更新
本文内容对应旧版平台与旧版资源,其内容不再适合最新版平台,请查看新版平台的使用说明
新版量化开发IDE(AIStudio):
https://bigquant.com/wiki/doc/aistudio-aiide-NzAjgKapzW
新版模版策略:
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
新版数据平台:
https://bigquant.com/data/home
https://bigquant.com/wiki/doc/dai-PLSbc1SbZX
新版表达式算子:
https://bigquant.com/wiki/doc/dai-sql-Rceb2JQBdS
新版因子平台:
https://bigquant.com/wiki/doc/bigalpha-EOVmVtJMS5
\
前言
featuretools有专门的 transfrom 类的特征处理方式,但是我在实际使用中没有使用,因为featuretool的思路是凡是能够进行特征变换的特征都要应用一遍,所以应用的模式基本上是生成大量的性能不强的特征,下一步必须进行严格的。
所以今天尝试用gplearn进行一下特征工程,本人能力有限,如有错误还请指正,也欢迎交流。
gplearn
gplearn是Python内最成熟的符号回归算法实现,作为一种一种监督学习方法,符号回归(symbolic regression)试图发现某种隐藏的数学公式,以此利用特征变量预测目标变量。
符号回归的具体实现方式是遗传算法(genetic algorithm)。一开始,一群天真而未经历选择的公式会被随机生成。此后的每一代中,最「合适」的公式们将被选中。随着迭代次数的增长,它们不断繁殖、变异、进化,从而不断逼近数据分布的真相。更详细的介绍可以参考:一文读懂遗传算法(附python)
当然我这里不是想尝试符号回归的机器学习方式,而是符号回归的机器学习方式提供了另外一种生成特征的思路,在库中通过Symbolic Transformer 类进行有关特征工程相关操作。
本文还是以 Home Credit Default Risk 110这个项目进行说明。
gplearn应用
在手工特征工程中,我们会对两个或者多个特征进行一些加减乘除的操作,来生成一些特征,希望能够生成一些。例如在start-here-a-gentle-introduction 79的这篇kernel中,根据领域的先验知识,对金额特征, 日期特征进行比值操作生成一些特征,这些特征经常能够提升验证集和测试集的分数,在模型中也有很高的重要程度。
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']
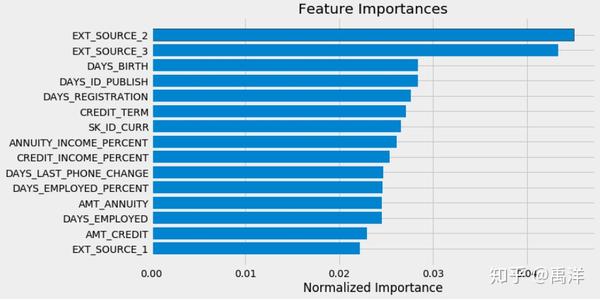 但毕竟领域的先验知识是有限的,我们有时候也没有足够的先验知识,同时自己进行特征组合也经常费时费力,自己生成的大量特征不是都有足够的重要性,还需要进一步筛选。
但毕竟领域的先验知识是有限的,我们有时候也没有足够的先验知识,同时自己进行特征组合也经常费时费力,自己生成的大量特征不是都有足够的重要性,还需要进一步筛选。
gplearn这个库提供了解决的思路: - 随机化生成大量特征组合方式,解决了没有先验知识,手工生成特征费时费力的问题 - 通过遗传算法进行特征组合的迭代,而且这种迭代是有监督的迭代,存留的特征和label相关性是也来越高的,大量低相关特征组合会在迭代中被淘汰掉,用决策树算法做个类比的话,我们自己组合特征然后筛选,好比是后剪枝过程,遗传算法进行的则是预剪枝的方式。
变异的方式有兴趣的可以看看文档 变异 57,具体遗传算法的方式我只是看看思路,并没有仔细推导。官方给出的 例子 114 是用 sklearn中自带的波士顿房价数据来进行特征组合,但是只是给出了一个新生成的特征缺失提升了测试集的效果的结论。
所以,尝试还是用官方的数据,探索一下新生成的特征到底表现如何。
从以下几个方面考察:
- 特征和label的相关性
- 特征之间的共线性
- 特征在模型中的重要程度
- 特征对模型性能的提升
策略源码
具体代码如下 ,可直接克隆,查看源码:
https://bigquant.com/experimentshare/a0f9d79cb3ff4aef9468671598e2e8bd
\