机器学习
机器学习在金融领域的应用日益广泛,为金融业务的智能化提供了强大动力。它运用算法和模型,自动从海量数据中学习和提取有用信息,无需人工进行复杂编程。在金融风控方面,机器学习技术可帮助银行、保险公司等机构更准确地识别欺诈行为,降低信贷风险。在投资策略上,通过对历史数据的深度学习,机器能预测市场走势,为投资者提供更精准的建议。同时,机器学习还能优化客户服务,例如通过聊天机器人提供24小时在线咨询,或根据客户行为数据提供个性化金融产品推荐。总的来说,机器学习不仅提升了金融业的效率和智能化水平,也在重塑我们的金融生态。
通过机器学习的经验资产定价(NBER-25398)
NBER工作论文第25398号,2018年12月,2019年9月修订
Shihao Gu 芝加哥大学布斯商学院
Bryan T. Kelly
耶鲁大学; AQR资本管理有限责任公司;美国国家经济研究局 (NBER)
Dacheng Xiu 芝加哥大学布斯商学院
摘要
我们对机器学习方法的典型问题进行了比较分析经验资产定价:衡量资产风险溢价。我们展示了巨大的经济收益投资者使用机器学习预测,在某些情况下将领先的业绩翻倍文献中基于回归的策略。我们确定性能最佳的方法(树和神经网络)并追踪它们的预测增益以允许非线性预测器其他方法错过的交互。所有方法都同意同一组显性预测信号,包括动量、流
更新时间:2021-12-08 03:48
超参搜索状态保存
test h1
test h2
test h3
test h1
\
更新时间:2021-11-30 03:40
跟着李沐学AI—Transformer论文精读 【含研报及视频】
原研报标题:Transformer: Attention is all you need
发布时间:2017年
作者:Ashish Vaswani、 Noam Shazeer、 Niki Parma 、Jakob Uszkoreit、 Llion Jones 、Aidan N. Gomez、 Łukasz Kaiser
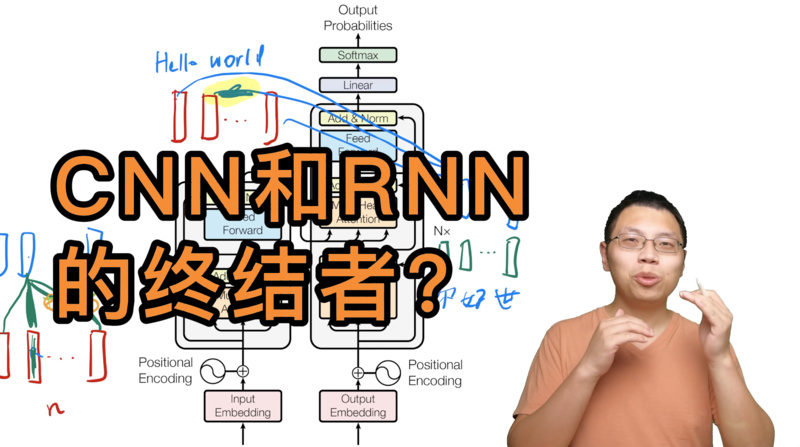 摘要
摘要
主流的序列转换模型都是基于复杂的循环神经网络或卷积神经网络,且都包含一个enc
更新时间:2021-11-30 03:07
基于小波分析和支持向量机的指数预测模型-国信证券-20100621
摘要
支持向量机(support vector machine,SVM)是数据挖掘中的一项新技术,是借助于最优化方法解决机器学习问题的新工具。它成为克服“维数灾难”和“过学习”等传统困难的有效办法,虽然他还处在飞速发展的阶段,但它的理论基础和实现途径的基本框架已经形成。支持向量机目前主要用来解决分类问题(模式识别,判别分析)和回归问题。而股市行为预测通常为预测股市数据的走势和预测股市数据的未来数值。而当我们将走势看作两种状态(涨、跌),问题便转化为分类问题,而预测股市未来的价格是指为典型的回归问题。我们有理由相信支持向量机可以对股市进行预测。
本报告将从实际应用角度出发,用沪深300
更新时间:2021-11-26 08:52
机器学习在基金绩效评价模型中的应用
摘要
在基金产品实际运行管理的过程中,基金绩效评价具有较 强的现实意义。基金公司管理者对基金经理的业绩考核、 基金经理对历史业绩的原因分析,都需要以科学的绩效归因和 评价模型为依据。
早期的基金评价主要评价基金的收益、超额收益、夏普 率、最大回撤等较为直观的指标。对基金的风格类型、收益来 源、选股能力、风险控制等方面还没有较为客观的评价。在实 践过程中发现,这种方式对于不同主题、不同风格类型的基金 经理的评价缺乏客观性。例如 :一只策略为单纯买入小市值股 票的基金,在 2014 年到 2015 年间,能够取得非常可观的业绩,在许多指标上的表现也可能较为优秀。但是这样的基 金其实存在非
更新时间:2021-11-26 07:56
机器学习系列报告之一:量化投资新起点-申万宏源-20200901
摘要
机器学习是人工智能的一个分支,也是人工智能的核心领域。机器学习的目的在于推理,推理的过程是学习,研究计算机如何模拟人类的学习行为。从1930年代至今,机器学习逐渐发展成为一门独立的学科,已有超过数百种算法被提出。《Do we need hundreds of classifiers to solve real world classification problems?》对17大类共179个分类器,在121个数据集上进行了测试。结果显示,随机森林和支持向量机(高斯核)效果最好,其次是神经网络和Boosting集成方法。
机器学习的一大发展趋势是大众化。早期的机器学习研究人员不仅
更新时间:2021-11-26 07:50
金融科技(Fintech)和数据挖掘研究(七):基于机器学习和知识图谱的行业轮动-海通证券-20200721
摘要
研究背景
我们在之前的行业轮动系列报告中挖掘了几大类的行业因子,例如,量价、宏观、情绪面、高频因子、预期基本面、历史基本面、公募基金观点等。这些因子通常可以分为两类:行业本身的特征以及基于共同外生变量变动的行业预期收益,但这两类因子都没有考虑行业之间的关联性。因此,在本篇报告中,我们从另一个角度研究行业收益的可预测性:相关行业的滞后收益率。
理论基础
投资者处理信息的能力有限,当某个行业出现信息或冲击时,专门从事相关行业的投资者可能也无法迅速把握冲击的全部影响。因此,信息会逐渐在各个行业间扩散,导致不同行业的股票价格先后响应。这一现象构成了某些行业滞后收益率
更新时间:2021-11-26 07:44
机器学习和知识图谱在行业轮动中的应用-海通证券-20200525
摘要
我们在行业轮动系列报告中挖掘了几大类的行业因子,这些因子通常都是行业本身的特征或者基于共同外生变量变动的行业预测收益。
今天我们从另一个角度研究行业收益的可预测性:相关行业的滞后收益率
实际上,如果市场完全理性、无摩擦,滞后行业的收益率是不应该有预测效果的。但真实的市场环境下并非如此。
Lasso回归,全称Least absolute shrinkage and selection operator。该方法是一种压缩估计,也被称作线性回归的L1 正则化。相比于普通最小二乘估计,它通过构造一个惩罚函数,在变量众多的时候快速有效地提取出重要变量,简化模型。其目标函数的表达式如下
更新时间:2021-11-26 07:43
机器学习系列报告之五:锦上添花,机器学习算法助力组合优化-光大证券-20200222
摘要
因子研究一直是量化领域的重心。研究者在基于新数据新想法不断努力挖掘有效因子的同时,如何将手头上已有的因子转化为最终的投资组合也是摆在基金经理们眼前的现实问题。本篇报告的主要研究目的,是在给定最终复合因子的前提下,探索新的多头股票组合构建及优化方式,并运用机器学习算法实现具有操作意义的指数增强构建方法。
因子组合构建方式不多:多为线性优化
线性优化是主流的因子组合构建方式之一,它有着简单直观、优化计算复杂程度低,计算耗时极少的优点。但相应的,它的不足之处是丢弃了不同个股之间的相关性信息,同时会使得最终的优化结果中,个股集中程度较大。
二次规划带来的边际提升有限
更新时间:2021-11-26 07:43
机器学习视角下的考察:因子拥挤度指标及其择时作用-招商证券-20200202
摘要
美国市场对于因子拥挤度指标的重视源于2009年动量因子(Momentum Factor)的大幅回撤,研究者认为因子拥挤度可能是影响因子寿命的重要原因。在国外研究的基础上,我们构建了估值价差、配对相关性、因子波动率、因子长期反转等8个因子拥挤度指标,并分别用这些指标对单因子收益方向和多因子组合权重进行了择时。在单因子择时方面,我们使用了XGBoost和LSTM两种机器学习算法,但是并没有取得明显优于纯做多方式的结果。我们又使用合成指标对多因子模型的权重进行调整,最后根据拥挤度指标加权后的多因子模型小幅战胜了因子等权组合的模型。
正像建筑师在设计公共建筑主体时,兼顾商业价值和美观之
更新时间:2021-11-26 07:37
中高频交易策略再出发:机器学习T0-安信证券-20191230
摘要
中高频机器学习再出发
区别于传统的主观规则交易,机器学习模型可以挖掘出更多的非线性模式。我们设计的集合分类回归策略采用XGBoost机器学习模型,并使用集合学习对机器学习模型进行融合来预测日内涨幅。
日内涨幅影响因子
我们共挖掘出15个因子:隔夜涨幅,集合竞价阶段第一阶段涨幅,集合竞价阶段成交金额占比,第一阶段委比变化,第二阶段委比变化,第二阶段涨停和第二阶段持续上行与日内涨幅有正向影响;集合竞价阶段第二阶段涨幅,集合竞价阶段成交金额占当天总成交金额的比例,第一阶段涨停,第二阶段的委买一价,委卖一价均值的平均值,第二阶段的委买一价,委卖一价均值的最大值,第二
更新时间:2021-11-26 07:37
人工智能研究报告:多周期机器学习选股模型-广发证券-20191204
摘要
选股模型的时效性
信息具有时效性。选股因子对股票收益率的预测能力会随着时间的延后而衰减。机器学习股票收益预测模型的目标是将股票因子与股票未来收益率关联起来。股票因子蕴含的信息决定了模型的预测能力,包括预测准确度和预测窗口长度。如果机器学习模型所用的股票因子中包含的是市场短期情绪面的信息,那么训练出来的机器学习模型可能对市场短期走势的预测能力较强;如果机器学习模型所用的因子包含的是市场中长期的价格扭曲信息,那么训练出来的机器学习模型可能对市场中长期的预测能力较强。
模型构建
本报告按照因子在不同预测窗口长度的IC将选股因子分成不同的组别,并针对不同的股票收益预
更新时间:2021-11-26 07:36
系统化资产配置系列之三:基于AdaBoost机器学习算法的市场短期择时策略-兴业证券-20191017
摘要
本篇是系统化资产配置系列报告的第三篇,对如何利用机器学习算法进行短期市场择时进行了系统介绍。全球金融市场每天产生海量的各类数据,如何筛选并有效利用这些数据来预测股票市场走势一直是一个重要但棘手的问题。短期择时面临的主要困难包括:
- 短期市场走势受情绪等因素影响较大;
- 如何筛选有效因子;
- 非线性因子如何建模;
- 因子相关性问题如何解决;
- 因子较多时如何避免过拟合等。
**幸运的是,机器学习技术的发展给我们提供了一条有效利用并筛选大量因子数据的途径。本报告中,我们将股市未来的涨和跌定义为一个分类问题,利用机器学习算法来对Wind全A指数的未来
更新时间:2021-11-26 07:36
机器学习实战系列之三:截面融合模型选股框架初探-长江证券-20180311
摘要
截面融合模型选股框架设计
截面融合模型包括三个部分:选择合适的特征空间,选取特定的模型簇,确定融合规则。目前常见的机器学习模型选股多将全部因子作为输入,以单个训练的模型作为预测结果,而截面模型框架通过在特征空间和函数空间进行选择,将多个特征空间下的多个函数簇在特定目标确定的规则下进行融合,达到更加逼近预测关系的结果。
筛选的多个子空间比全空间表现更好,且可以很好捕捉非线性关系
本文从特征子空间和多个解释空间这两个角度出发验证筛选因子空间的有效性,从超额收益、夏普比、信息比、多空夏普比和Calmar比上进行对比,多个大类行业的子空间的策略表现显著优于全空间策略
更新时间:2021-11-26 07:34
机器学习实战系列之二:收益复制的LASSO回归方法实践-长江证券-20171206
摘要
收益复制策略的应用场景
广义的收益复制策略在许多场景中都有应用价值。较为典型的收益复制应用情景包括三类:(1)极小型股票池、低调仓频率实现宽基指数跟踪;(2)通过直接持有底层资产,近似模拟基金组合收益,降低管理费用;(3)在持股受限的情形下解决受限个股替代性持仓的权重分配问题。同时,海外市场中的对冲基金指数ETF产品的设计思路对我们也有一定的参考意义。
核心方法:LASSO回归筛选和二次优化模型
系统化地实现收益复制框架并非易事,它需要回答两个核心问题:选什么股票和如何在它们之间进行权重配置。通过机器学习方法中的LASSO回归模型筛选最优股票池,然后求解二次
更新时间:2021-11-26 07:34
华泰人工智能系列之三十:从关联到逻辑,因果推断初探-华泰证券-20200424
摘要
本文介绍了因果推断的框架,并研究了股票所属概念和收益的因果关系
人工智能领域中,机器学习的优势在于强大的关联挖掘能力,然而由于缺乏逻辑推理能力,机器学习无法区分数据中的因果关联和虚假关联。因果推断是用于解释分析的建模工具,可帮助恢复数据中的因果关联,有望实现可解释的稳定预测。本文介绍了基于倾向性评分法的因果推断框架,归纳了三个关键步骤,并分别在Lalonde数据集和A股概念数据中进行因果效应估计。结果显示,2016年以来在中证800成分股中,基金重仓(季调)概念与股票未来一个月收益有正向因果关系,股票质押概念与股票未来一个月收益有反向因果关系,预增和护城河概念与股票收益
更新时间:2021-11-26 07:32
华泰人工智能系列之十二:人工智能选股之特征选择-华泰证券-20180725
摘要
特征选择是人工智能选股策略的重要步骤,能够提升基学习器的预测效果
特征选择是机器学习数据预处理环节的重要步骤,核心思想是从全体特征中选择一组优质的子集作为输入训练集,从而提升模型的学习和预测效果。我们将特征选择方法应用于多因子选股,发现特征选择对逻辑回归_6m、XGBoost_6m基学习器的预测效果有一定提升。我们以全A股为股票池,以沪深300和中证500为基准,构建行业中性和市值中性的选股策略。基于F值和互信息的方法对于逻辑回归_6m、XGBoost_6m、XGBoost_72m基学习器的回测表现具有明显的提升效果。
**随着入选特征数的增加,模型预测效果先上升后下
更新时间:2021-11-26 07:28
金工研究:华泰人工智能系列之七-人工智能选股之Python实战-华泰证券-20170912
摘要
介绍Python安装方法、与机器学习相关的包以及常用命令
Python语言是目前机器学习领域使用最广泛的编程语言之一,拥有众多优秀的包和模块,并且相对简单易学。我们将简单介绍Python语言的特性,常用命令,以及和机器学习相关的包,例如NumPy,pandas,scikit-learn等,希望帮助有一定编程基础的读者迅速上手Python语言。
机器学习选股框架与多因子选股框架类似,具有一定优越性
机器学习中最为主流的方法监督学习,其核心思想是挖掘自变量和因变量之间的规律。我们将经典多因子模型稍加改造,以机器学习的语言描述。在训练阶段,根据历史的因子值X和收益
更新时间:2021-11-26 07:28
华泰人工智能系列之四:人工智能选股之朴素贝叶斯模型-华泰证券-20170817
摘要
本报告对朴素贝叶斯模型及线性判别分析、二次判别分析进行系统测试
“生成模型”是机器学习中监督学习方法的一类。与“判别模型”学习决策函数和条件概率不同,生成模型主要学习的是联合概率分布𝑃(𝑋,𝑌)。本文中,我们从朴素贝叶斯算法入手,分析比较了几种常见的生成模型(包括线性判别分析和二次判别分析)应用于多因子选股的异同,希望对本领域的投资者产生有实用意义的参考价值。
朴素贝叶斯模型构建细节:月频滚动训练,结合基于时间序列的交叉验证
朴素贝叶斯模型的构建包括特征和标签提取、特征预处理、训练集合成和滚动训练等步骤。我们的模型设置为月频换仓,在每个月月底重新训练并
更新时间:2021-11-26 07:28
选股因子系列研究(六十四):基于直观逻辑和机器学习的高频数据低频化应用-海通证券-20200424
在系列前期报告中,我们从不同角度探寻了分钟成交数据、TICK盘口委托数据以及逐笔数据中所包含的选股能力。研究结果表明,高频数据中包含着较为显著的选股能力。即使在剔除了常规低频因子的影响后,高频因子依旧具有显著的选股能力。考虑到系列前期报告在研究构建高频因子时,大多仅使用某一类高频数据进行因子构建,并未将相关数据搭配使用。本文从逻辑以及机器学习两个角度出发,尝试将不同类别的高频数据混合使用并构建低频选股因子。
买入意愿与主动买入的结合。总结前期研究成果可知,委托挂单数据中包含了投资者还未释放的交易意愿,而逐笔成交数据中包含了投资者已进行的交易行为。两者的结合能够更加全面地刻画投资者的交易意愿。
更新时间:2021-11-22 09:43
《因子选股系列研究之二十八》:用机器学习解释市值,特异市值因子-东方证券-20170804
在某个时点上的股票的横截面市值基本上都可以被公司的财务指标和市场因素所解释,也就是说市值解释模型依据了市场上股票的情况,给出了每个公司当期投资者认为的内生市场价值,而解释模型的残差部分,也就是当前市值和内生市值的差,代表了不可解释的部分。残差值越大,代表公司当前的市值向上偏离内生市值越多,那么公司的市值越倾向于回复到其内生市值,也就是说公司股价下跌的可能性越大,反之亦然,特异市值(残差值)是一个相对估值指标,因子值较小的股票在未来表示
我们用线性模型构建了特异市值指标,发现虽然因子表现较好,但是增量信息不明显,究其原因是因为线性的方法没有办法解释市值与财务指标之间的非线性关系,所以导致回归的
更新时间:2021-11-22 07:53
《因子选股系列研究之十五》:东方机器选股模型Ver1.0-东方证券-20161107
机器学习容易给人“黑箱模型”和“过拟合”的印象,但事实上一些机器学习算法的逻辑和结果都非常直白,而且算法自身带有一套避免过拟合的参数估计机制。众多的实践研究说明,机器学习方法的预测能力大部分情况下都强于线性模型,很值得在量化投资中测试使用。本报告主要讲述机器学习的基本原理和用其来做量化选股的实证结果
机器学习模型众多,不存在所谓的最强模型,不同的数据,不同的问题适用不同的模型。我们测试了LASSO、SVM、增强型决策树、随机森林等几种常见机器学习方法,最终选择用随机森林,主要是因为它结构简单、参数少、过拟合概率低,同时还具有非常强的样本外预测能力
机器选股模型省去了“因子筛选”、“因子加权
更新时间:2021-11-22 07:53
实盘数据同步功能
机器学习在股票市场上应用价值初见成效,不少机器学习的策略远远超过大盘。虽然目前平台的实盘交易功能还未对外开放,但是不少策略开发者已经在实盘跟踪自己的策略了。
1.功能背景
用户在实盘中可能会遇到实盘账户数据和模拟交易运行数据不一致的情形,比如模拟交易的交易计划里提醒今天收盘时卖出A股票1000股,但今天碰巧由于断网导致卖单失败了。于是当日清算后,模拟交易策略里没有1000股A,但是实盘账户里该股票还继续持有。 策略次日会买入新股票,但实际由于收盘卖出失败,其实没有资金买入新股票。如果不对此类问题进行调整处理的话,随着交易日逐渐增多,那么实盘和模拟交易的差异会逐渐扩大,时间长了会
更新时间:2021-11-19 11:07
CTA程序化交易实务研究之六:基于机器学习的订单簿高频交易策略-民生-131211
更新时间:2021-11-12 11:39
【精品】全网人工智能机器学习免费资源汇总清单
作者:Robbie Allen
编译:BigQuant
早在21世纪初,我在编写关于网络和编程的书的时候,我就发现,互联网是一个很好的资源,但是它还不完善。 那时,博客已开始流行。但是YouTube还不是很普遍,同样Quora,Twitter和播客用户也很少。十年过后,我一直在潜心钻研人工智能和机器学习,局面发生了翻天覆地的变化。互联网上现在有非常丰富的资源——当你要寻找选择你想要的资源时,你很难抉择你应该从哪里开始(和停止)!
![微信图片_20180306160704|690x277](/community/uploads/default/original/2X/5/
更新时间:2021-11-11 07:27