Transformer
从金融角度来看,"Transformer"不仅仅是一种在自然语言处理中广泛应用的深度学习架构,还是金融科技领域的重要技术支撑。Transformer通过自注意力机制实现信息的全局交互与高效处理,能够处理大规模、非结构化的金融数据,如市场报告、新闻舆情等,从而挖掘出有价值的市场趋势、风险因子及投资机遇。此外,其在金融预测模型中的应用,显著提高了预测的准确性与时效性,为量化交易、风险管理、智能投顾等金融场景提供了强大的技术支持。随着金融科技的不断发展,Transformer有望成为金融行业智能化转型的关键技术之一。
如何解读Transformer等深度学习中序列窗口滚动模块功能
问题
transformer等深度学习中序列窗口滚动模块具体的功能是什么,为什么要把数据做这个处理,能否用numpy的源码写一个函数?
视频
https://www.bilibili.com/video/BV1i44y1q7As?p=4&share_source=copy_web
策略源码
2021年7月8日Meetup策略模板:
[https://bigquant.com/experimentshare/6235b7c
更新时间:2025-12-30 06:37
大模型核心概念与API上手
大模型(Large Language Model, LLM)是指包含大规模参数(通常达千亿甚至万亿级别)、使用海量文本数据训练而成的深度学习模型。
其“大”主要体现在三个维度:模型参数规模大、训练数据规模大(例如ChatGPT的预训练数据量达到45TB)和算力消耗需求大。
当前,最具代表性的大模型(如GPT系列、Claude、文心一言等)大多基于Transformer架构,该架构使其能够高效处理序列数据,具备强大的语言理解和内容生成能力。\n对于开发者而言,一个关键认知在于:大模型应用开发的核心,绝大多数情况下并非从零开始训练模型,而是基于现有的成熟模型API进行集成和二次开发,通过设
更新时间:2025-12-05 03:38
【代码报错】Transformer模型固化后预测出错?
\
更新时间:2025-02-16 01:06
【平台使用】bug:transformer代码不能自动调用GPU
1.从论坛拷过去的
transformer代码,不会自己调用GPU
2.在fai平台跑的时候,会报类加载不了
代码地址:https://bigquant.com/wiki/doc/moxing-zhineng-celve-Aq5HupQJrB
更新时间:2025-02-15 14:44
【平台使用】Transformer模板策略报错问题,优化函数应该如何设置?
拷贝的训练营的策略,之前可以跑,现在跑不了了。
策略链接:
https://bigquant.com/wiki/doc/-zCgXuhm72a
报错提示:
--> 351 m33 = M.cached.v3( 352 input_1=m2.data, 353 input_2=m32.data,
<ipython-input-2-a70fc4bd659b> in m33_run_bigquant_run(input_1, input_2, input_3) 16 from bigmodels.models.transformer import Tran
更新时间:2025-02-15 14:28
基于分层多尺度的高斯Transformer
原标题:Hierarchical Multi-Scale Gaussian Transformer for Stock Movement Prediction
时间:2020年
作者:
摘要
由于金融市场的不确定性,预测股票等金融证券的价格走势是一项重要而具有挑战性的任务。本文提出了一种新的基于Transformer的股票移动预测方法。此外,我们还对提出的基本Transformer进行了一些增强。首先,提出了一种多尺度高斯先验增强Transformer局部性的方法。其次,我们提出了一种正交正则化方法,以避免在多头自注意机制中学习多余头。然后,我们设计了一个用于Transf
更新时间:2025-01-09 10:48
基于Transformer模型的智能选股策略
旧版声明
本文为旧版实现,仅供学习参考。
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU(新版开发环境下的模版目录)
\
导语
RNN、LSTM和GRU网络已在序列模型、语言模型、机器翻译等应用中取得不错的效果。循环结构(recurrent)的语言模型和编码器-解码器体系结构取得了不错的进展。
但是,RNN固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。这样,一是使得RNN的训练时间会相对比较长,对其的优化方法也比较少,二是对于长时间记忆来说,其的效果也大打折扣。
而Tr
更新时间:2024-09-04 01:21
Transformer模型训练好以后如何固化?
如题,训练一次Transformer模型很不容易,训练完成以后如何固化呢?用固化深度模型的方法没办法存储。
提示如下:
ValueError Traceback (most recent call last) <ipython-input-17-6cbf37e6754a> in <module> 1 print(m4.data) 2 ds = m4.data ----> 3 pd.DataFrame([DataSource(ds.id).read()]).to_pickle('/
更新时间:2023-06-01 02:13
DeepAlpha短周期因子系列研究之:Transformer在量化选股中的应用
\
一、引言
Google在2017年发布了Transformer,截止2022年5月,《Attention is all you need》论文的引用量已经超过了4万,可以说是近5年最热门的论文。
Transformer最初发布是用于时序任务和NLP任务,在近年来也有不少Transformer在CV应用比较出色的研究,我们有理由相信Transformer也可以应用于量化投资领域。
二、Transformer
Transformer的基本思想可以从平台之前发布的文章中看到,本文就不再进行重述。
<https://bigquant.com/wiki/doc/moxing-z
更新时间:2023-03-16 11:59
基于Transformer模型的智能选股策略
导语
RNN、LSTM和GRU网络已在序列模型、语言模型、机器翻译等应用中取得不错的效果。循环结构(recurrent)的语言模型和编码器-解码器体系结构取得了不错的进展。
但是,RNN固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。这样,一是使得RNN的训练时间会相对比较长,对其的优化方法也比较少,二是对于长时间记忆来说,其的效果也大打折扣。
而Transformer的核心,注意力机制(Attention)允许对输入输出序列的依赖项进行建模,而无需考虑它们在序列中的距离,这样对上面两个RNN中比较突出的问题就有了一个比较好的解决办法。本文将
更新时间:2022-11-03 08:33
Transformer使用文档
简介
Transformer:Attention is all you need
paper: https://arxiv.org/abs/1706.03762
The naive transformer implemented here for financial time series prediction follows the paper "Attention is all you need": Given the input (N, T, F)
- An embedding layer that maps the input (N, T, F) to repres
更新时间:2022-09-15 13:09
跟着李沐学AI—Transformer论文精读 【含研报及视频】
原研报标题:Transformer: Attention is all you need
发布时间:2017年
作者:Ashish Vaswani、 Noam Shazeer、 Niki Parma 、Jakob Uszkoreit、 Llion Jones 、Aidan N. Gomez、 Łukasz Kaiser
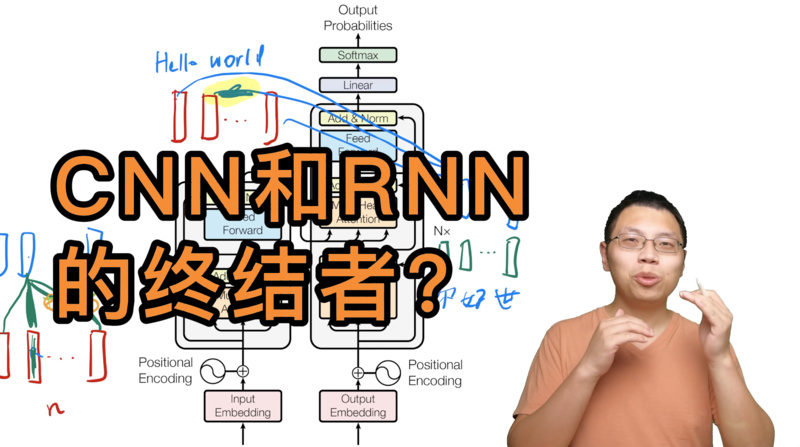 摘要
摘要
主流的序列转换模型都是基于复杂的循环神经网络或卷积神经网络,且都包含一个enc
更新时间:2021-11-30 03:07
基于Transformer的Capsule网络股票走势预测
作者:Jintao Liu1∗ , Xikai Liu1∗ , Hongfei Lin1† , Bo Xu1,2 , Yuqi Ren1 , Yufeng Diao1,3 , Liang Yang1 1
时间:2020年
原文标题:Transformer-Based Capsule Network For Stock Movements Prediction
摘要
股票走势预测对于研究和行业来说都是一项极具挑战性的研究。利用社交媒体预测股市走势是一项有效但困难的任务。然而,现有的基于社交媒体的预测方法往往没有考虑到特定股票的丰富语义和关联。这就导致了有效编码的困难。为了解决这一问题
更新时间:2021-11-02 03:42
基于Transformer模型的智能选股策略
导语
RNN、LSTM和GRU网络已在序列模型、语言模型、机器翻译等应用中取得不错的效果。循环结构(recurrent)的语言模型和编码器-解码器体系结构取得了不错的进展。
但是,RNN固有的顺序属性阻碍了训练样本间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。这样,一是使得RNN的训练时间会相对比较长,对其的优化方法也比较少,二是对于长时间记忆来说,其的效果也大打折扣。
而Transformer的核心,注意力机制(Attention)允许对输入输出序列的依赖项进行建模,而无需考虑它们在序列中的距离,这样对上面两个RNN中比较突出的问题就有了一个比较好的解决办法。本文将
更新时间:2021-07-03 14:26