神经网络
神经网络是一种受生物大脑神经结构启发的计算方法,已成为现代金融领域的重要工具。其强大的模式识别和预测能力,使得金融市场分析、风险管理和投资策略制定得以显著提升。在金融应用中,神经网络能够从海量的历史数据中学习和识别复杂的非线性关系,进而预测市场趋势、评估信贷风险或检测欺诈行为。与传统的统计模型相比,神经网络更能够适应快速变化的市场环境,为金融机构提供更加精准和及时的决策支持。然而,尽管神经网络在金融领域具有巨大潜力,其应用也面临着数据质量、过拟合和解释性等方面的挑战。
使用神经网络进行端到端风险预算投资组合优化
论文原名
End-to-End Risk Budgeting Portfolio Optimization with Neural Networks
论文作者
A. Sinem Uysal, Xiaoyue Li , and John M. Mulvey
修订时间
2021年7月9日
引言
投资组合优化一直是金融领域的核心问题,经常与两个步骤:校准参数,然后解决优化问题。然而,两步过程有时会遇到“误差最大化”问题,其中参数估计的不准确转化为不明智的分配决策。在这论文中,我们将预测和优化任务结合在一个单一的前馈神经网络中网络并实施端到端的方法,在那里我们学习
更新时间:2021-12-28 02:40
限价订单簿的多视角预测:新颖的深度学习方法和硬件使用智能处理单元加速
论文原名
Multi-Horizon Forecasting for Limit Order Books:Novel Deep Learning Approaches and Hardware Acceleration using Intelligent Processing Units
论文作者
Zihao Zhang, Stefan Zohren Oxford-Man Institute of Quantitative Finance, University of Oxford
修订时间
2021年8月27日
引言
我们为限价订单 (LOB) 数据设计
更新时间:2021-12-28 02:21
Delta Hedging 的神经网络
论文原名
NEURAL NETWORKS FOR DELTA HEDGING
论文作者
Guijin Son and Joocheol Kim
发布时间
2021 年 12 月 21 日
引言
在完美金融市场假设下定义的 Black-Scholes 模型,理论上创建一个完美的对冲策略,允许交易者规避期权组合中的风险。然而,“完美金融市场”的概念,要求零交易和持续交易,在现实世界中遇到是具有挑战性的。尽管存在如此广为人知的局限性,但学者们已经未能开发出足够成功的替代模型以建立长期。在本文中,我们通过测试对冲探索基于深度神经网络 (DNN) 的对冲系统的前景以
更新时间:2021-12-21 02:38
跟着李沐学AI—GAN论文精读 【含研报及视频】
原研报标题:Generative Adversarial Nets
发布时间:2018年
作者:Ian J. Goodfellow∗, Jean Pouget-Abadie† , Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair‡ , Aaron Courville, Yoshua Bengio
摘要
本文通过对抗过程,提出了一种新的框架
更新时间:2021-11-30 03:08
跟着李沐学AI—Transformer论文精读 【含研报及视频】
原研报标题:Transformer: Attention is all you need
发布时间:2017年
作者:Ashish Vaswani、 Noam Shazeer、 Niki Parma 、Jakob Uszkoreit、 Llion Jones 、Aidan N. Gomez、 Łukasz Kaiser
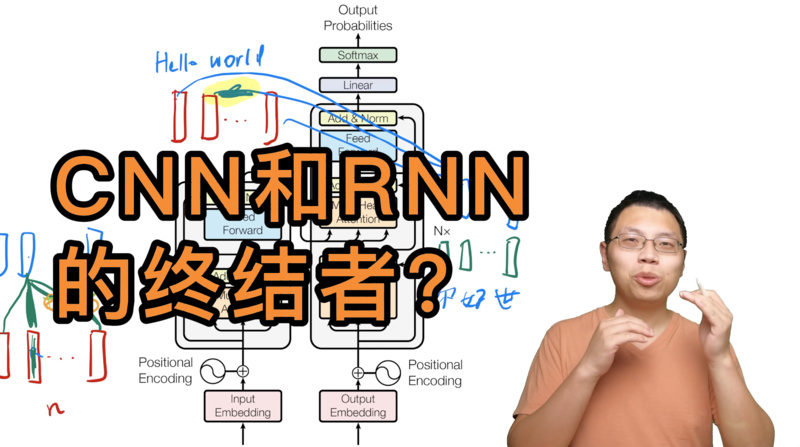 摘要
摘要
主流的序列转换模型都是基于复杂的循环神经网络或卷积神经网络,且都包含一个enc
更新时间:2021-11-30 03:07
神经网络日频alpha模型初步实践
摘要
多因子体系主要包括alpha模型、风险模型、交易成本模型和组合优化,广义的alpha模型分为alpha因子构建和因子加权,是量化从业人员的研究重心但传统的alpha模型当期面临较大的挑战。
后发优势的逐渐丧失导致人工挖掘alpha因子的周期变长,国内外估值因子的长时间回撤,近年量价因子的批量拥挤等都是当前选股alpha因子层面的困境,量价因子拥挤等原因导致因子IC和组合绩效产生较大偏差,给以IC和回归为基础的动态因子加权带来挑战
除了人工合成alpha因子外,我们可以通过设计因子单元批量产生有效的alpha因子,以扩充因子库,考虑到因子IC和组合收益的不一致性,我们通过正交弱
更新时间:2021-11-26 07:56
神经网络交易算法
更新时间:2021-09-08 03:03
用多层感知器-回归算法实现A股股票选股
更新时间:2021-07-30 07:26