神经网络
神经网络是一种受生物大脑神经结构启发的计算方法,已成为现代金融领域的重要工具。其强大的模式识别和预测能力,使得金融市场分析、风险管理和投资策略制定得以显著提升。在金融应用中,神经网络能够从海量的历史数据中学习和识别复杂的非线性关系,进而预测市场趋势、评估信贷风险或检测欺诈行为。与传统的统计模型相比,神经网络更能够适应快速变化的市场环境,为金融机构提供更加精准和及时的决策支持。然而,尽管神经网络在金融领域具有巨大潜力,其应用也面临着数据质量、过拟合和解释性等方面的挑战。
神经网络算法下的风格轮动策略
我们之前已经介绍过几个风格轮动的策略了,本质上依据的就是股票市场长期存在的“强市炒成长、弱市求稳健”的轮动策略。
1.神经网络算法
1.1算法核心原理
神经网络是一种模仿人脑神经元连接结构的机器学习模型,擅长处理多维度、非线性的复杂数据关系。其核心优势在于通过多层网络结构自动学习数据中的隐藏规律,无需人工预设特征映射关系,能更精准捕捉市场风格背后的复杂驱动逻辑。
1.2神经网络架构设计
我们采用的是全连接神经网络,具体的结构如下:
- 输入层:接收 6 个核心市场特征(市场广度指标 breadth_ma20、短期动量 avg_mom5、长期动量
更新时间:2026-03-17 02:52
深度学习在期货高频上的应用
问题
深度学习在期货高频上的应用
策略源码
8月19日Meetup问题模板:
https://bigquant.com/experimentshare/f58dbfb388454407b8a2b99eb14cf1ea
\
更新时间:2025-12-30 06:37
超参寻优调参顺序
更新时间:2025-12-30 06:37
如何在全连接层中自定义swish激活函数
问题
如何在全连接模块中自定义swish激活函数的代码
\
视频
https://www.bilibili.com/video/BV1DL4y1w7sb?share_source=copy_web
策略源码
[https://bigquant.com/experimentshare/9f1dae69e055429c9922b4f5d038361a](https://bigquant.com/experimentshare/9f1d
更新时间:2025-12-30 06:37
算法那么多,如何给策略选择最佳的算法?
\
作者
徐耀杰(woshisilvio)
常见算法优劣比较
算法没有最好,只有更好。 这个问题的答案取决于许多因素,例如股票市场的条件,数据集的质量和特征工程的有效等。接下来,我们来看看这些算法的优势和劣势:
- 神经网络:适用于复杂的非线性问题,可以有效地捕捉市场的非线性特征和复杂关系。
- 决策树:适用于数据量较小、特征维度较少的情况,可以很好地解释模型的决策过程。
- 随机森林:适用于处理高维度、复杂数据集,具有很好的鲁棒性和准确性。
- 支持向量机:适用于数据量较小、特征维度较高的情况,可以有效地处理非线性和线性可分问题。
正常情况下,在处理少量的股票量
更新时间:2025-12-30 06:37
简单网格交易日内择时
AI量化Meetup 2021年1月28日期问题,配合视频更容易理解。视频详见:
策略案例
https://bigquant.com/experimentshare/5dd6b4f7a29d4c5d827aeeff05816cfd
\
更新时间:2025-12-30 06:37
利用神经网络分析股票相关性
问题
如何利用神经网络分析股票之间的相关性,达到词向量空间的效果?
策略源码
https://bigquant.com/experimentshare/3dae29a664c84984a1ae6c65e62f51e0
视频
[https://www.bilibili.com/video/BV1Ma411N7KS?share_source=copy_web&vd_source=2e7dc1240ea373ea6eba1134
更新时间:2025-12-30 06:37
深度学习在期货高频上的应用
更新时间:2025-12-30 06:37
超参优化
更新
本文为旧版实现,仅供学习参考。
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
7月30日Meetup 模板案例:
策略案例
https://bigquant.com/experimentshare/99d8bec5248e4878b33a21bc119a6671
\
更新时间:2025-12-30 06:37
Bigmodels模型库
BigQuant AI Platform deep learning models(BigQuant AI量化平台深度学习模型库)。
介绍
bigmodels是什么?
bigmodels是BigQuant AI量化平台的深度学习模型库,集成了AI量化研究过程中常用的深度学习模型。
为什么需要bigmodels?
我们用PyTorch封装了AI量化研究中常用的深度学习模型,包含DNN、1DCNN、LSTM和Transformer等,并持续更新。
平台用户可以用简单的方式调用经过大量实践检验的AI能力,赋能AI量化投资。
import toch
impo更新时间:2025-06-02 07:02
混合 ARMA-GARCH-神经网络,用于高频交易中的日内策略探索
摘要
文章指出,在过去20年中,武装冲突的频率增加,这些冲突不仅影响社会层面,还对经济和金融领域产生重大影响。例如,“9·11”事件后,市场不确定性显著增加,投资受到抑制。地缘政治风险对经济周期和金融市场有显著影响,因此中央银行家和企业投资者常将地缘政治风险视为投资决策的重要因素。此外,地缘政治事件对不同行业的影响不同,例如旅游业可能受到负面影响,而国防行业则可能从中受益。
研究方法
方法文章提出了一个结合ARMA-GARCH模型和多种神经网络技术的混合模型,用于检测日内市场模式并预测国防股票市场和外汇市场的波动。这些技术包括:
- ARMA-GARCH-神经网络(NN)
更新时间:2025-04-22 10:38
机器学习常见算法
导语
机器学习里面究竟有多少经典的算法呢?本文简要介绍一下机器学习中的常用算法。这部分介绍的重点是这些方法内涵的思想,数学与实践细节不会在这讨论。
回归算法
在大部分机器学习课程中,回归算法都是介绍的第一个算法。原因有两个:一.回归算法比较简单,介绍它可以让人平滑地从统计学迁移到机器学习中。二.回归算法是后面若干强大算法的基石,如果不理解回归算法,无法学习那些强大的算法。回归算法有两个重要的子类:即 线性回归 和 逻辑回归 。
线性回归就是我们前面说过的房价求解问题。如何拟合出一条直线最佳匹配我所有的数据?一般使用“最小二乘法”来求解。“最小二乘法”的思想是
更新时间:2025-04-14 04:26
【指标定制】神经网络dnn模型sql标签怎么写,预测的时候总是维度不匹配,因为多了标签列
/* 使用DAI SQL为量化模型预测生成标签数据。标签反映了未来5日的收益率,并且被离散化为20个桶,每个桶代表一个收益率范围。这样,我们就可以训练模型来预测未来的收益率范围,而不仅仅是具体的收益率值。
- 首先定义了一个名为label_data的临时表,用于计算和存储未来5日收益率,其1%和99%分位数,以及离散化后的收益率(被分为20个桶,每个桶代表一个收益率范围)。
- 对未来5日收益率进行了截断处理,只保留在1%和99%分位数之间的值。
- 选择了标签值不为空,并且非涨跌停(未来一天的最高价不等于最低价)的数据
- 从这个临时表中选择了日期、股票代码和标签字段,以供进模
更新时间:2025-02-16 01:51
【平台使用】如何使用Pytorch
请问如何在代码中使用自定义的Pytorch神经网络并使用GPU加速?目前在文档中没有找到相关的描述,是否支持这种功能呢?
更新时间:2025-02-14 07:34
Machine Learning is Fun! — 全世界最简单的机器学习入门指南
你是否曾经听到过人们谈论机器学习,而你却对其含义只有一个模糊的概念呢?你是否已经厌倦了在和同事对话时只能点头呢?现在,让我们一起来改变这个现状吧!
这篇指南是为那些对机器学习感兴趣,但又不知从哪里开始的人而写的。我猜有很多人曾经尝试着阅读机器学习的维基百科词条,但是读着读着倍感挫折,然后直接放弃,希望能有人给出一个更直观的解释。本文就是你们想要的东西。
本文的写作目标是让任何人都能看懂,这意味着文中有大量的概括。但是那又如何呢?只要能让读者对机器学习更感兴趣,这篇文章的任务也就完成了。
什么是机器学习?
机器学习是一种概念:不需要写任何与问题有关的特定代码,泛型算法(Gene
更新时间:2024-12-04 08:53
华安证券-“学海拾珠”系列之一百七十三-基于端到端神经网络的风险预算与组合优化
更新时间:2024-06-18 06:13
Deep Learning with Python 终于等到你!
年初就一直在等啦
终于等到这本书
分享一下
此书的代码下载地址:https://github.com/fchollet/deep-learning-with-python-notebooks
?
目录
- 随机梯度下降法有什么问题?
- 负采样
- 计算梯度
1. 随机梯度下降法有什么问题?
通过对代价函数求权重的梯度,我们可以一次性对所有的参数 进行优化,但是如果每次等全部计算完成再优化升级,我们将等待很长时间(对于很大的语料库来说)。
所以我们采用随机梯度下降( Stochastic Gradient Descent),也就是说每次完成一次计算就进行升级。
但是,还有两个问题导致目前的模型效率低下!
第一个问题,我们每次只对窗口
更新时间:2024-06-12 06:06
Word2Vec介绍:skip-gram模型
本文是译文,原文戳这里.
本教程将介绍Word2Vec的skip-gram神经网络模型。本教程的目的是忽略Word2Vec的一般介绍性和抽象概念,深入了解skip-gram的更多的细节。
模型概述
skip-gram神经网络模型其最基本的形式实际上惊人的简单; 我认为是所有的细节和技巧使其难以解释。
我们先从高层次了解该模型。Word2Vec使用了一个在机器
更新时间:2024-06-12 06:06
997篇-历史最全生成对抗网络(GAN)论文串烧
什么是GAN?(本文内容整理自网络)
GAN(Generative Adversarial Netwo,生成对抗网络)是用于无监督学习的机器学习模型,由Ian Goodfellow等人在2014年提出,由神经网络构成判别器和生成器构成,通过一种互相竞争的机制组成的一种学习框架。
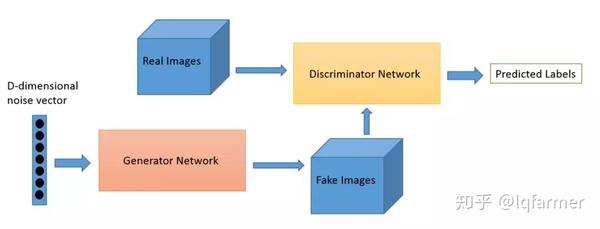 卷积神经网络之父-Yann LeCun这样评论GAN
卷积神经网络之父-Yann LeCun这样评论GAN
*在我看来,最重要的是对抗训练( GAN也称为生成对抗网络)。这一想法最初
更新时间:2024-06-12 06:04
卷积神经网络入门,卷积池化与非线性
-
Update At 2017年6月23日
本文作者: HackCV
\
什么是卷积神经网络?为什么它们很重要?
卷积神经网络(ConvNets 或者 CNNs)属于神经网络的范畴,已经在诸如图像识别和分类的领域证明了其高效的能力。卷积神经网络可以成功识别人脸、物体和交通信号,从而为机器人和自动驾驶汽车提供视力。

在上图中,卷积神经网络可以
更新时间:2024-06-12 06:03
多层感知器回归模型案例
本文内容已经过期,不再适合平台最新版本,请查看以下最新内容,作为参考资料学习。
旧版声明
本文为旧版实现,仅供学习参考。
https://bigquant.com/wiki/doc/demos-ecdRvuM1TU
\
策略案例
[https://bigquant.com/experimentshare/42bf93884b1246ad83c2874f06765732](https://bigquant.com/experimentshare/42bf93884b12
更新时间:2024-05-20 06:39
主动学习(Active Learning)
\
背景
机器学习的研究领域包括有监督学习(Supervised Learning),无监督学习(Unsupervised Learning),半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)等诸多内容。针对有监督学习和半监督学习,都需要一定数量的标注数据,也就是说在训练模型的时候,全部或者部分数据需要带上相应的标签才能进行模型的训练。但是在实际的业务场景或者生产环境中,工作人员获得样本的成本其实是不低的,甚至在某些时候是相对较高的,那么如何通过较少成本来获得较大价值的标注数据,进一步地提升
更新时间:2024-05-20 06:19