强化学习在金融市场中的应用(上)¶
前言¶
今年来,随着Alpha GO的闪亮登场,以及最近强化学习在dota2中战胜职业战队,强化学习越来越受到人们的关注。一直在关注金融领域的我,很自然地会问,那么强化学习应用在股票交易中会怎么样?
本文旨在揭开强化学习神秘的面纱,针对对这个领域感兴趣的读者普及强化学习的基本概念,以及强化学习在金融交易中的发展以及方向。
强化学习基本概念¶
强化理论最开始是心理学的概念,它是过程型激励理论之一,最早要追溯到美国的心理学家斯金纳。斯金纳认为人的行为是对其所获刺激的函数。如果这种刺激对他有利,则这种行为就会重复出现;若对他不利,则这种行为就会减弱直至消失。根据强化的性质和目的,可以分为正强化和负强化两大类型。斯金纳认为通过奖惩的设计,可以改变人或者动物的行为习惯。
在强化学习的基本概念和斯金纳的差不多,强化学习通过agent与环境的动作/交互Action,得到与之对应的奖励或者惩罚,并在这样的环境中进行迭代,与环境的交互意味着agent可以不断在经验中修正自己的决策,也就是policy。
大致框架如下图所示:
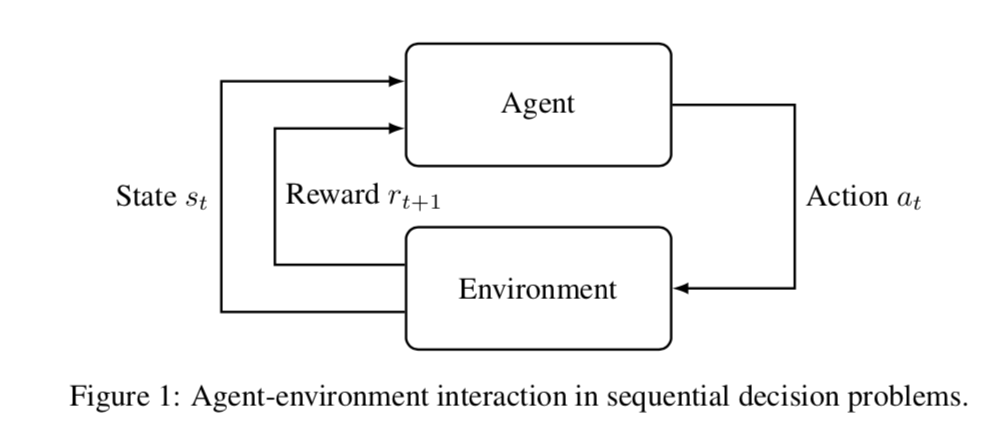
下面我们来举一个大家都熟悉的例子,来帮助大家理解强化学习的基本概念:

Pacman大家小时候在街机或者游戏机上可能都玩过,下面我们用强化学习的术语来定义pacman这个problem。
环境 Environment¶
在强化学习中,我们通常对环境的定义是所有于agent进行交互的东西。在我们这个例子里,pacman的环境包含了机器人agent的游戏世界,比如迷宫的形状、迷宫的不可穿墙性,也包含了游戏规则,比如机器人pacman可以吃豆子变无敌、无敌的时间、无敌时候可以吃掉敌人、敌人还可以再生等等。简单说是可以可以容纳agent的一个“容器”,同时它有它自己的世界和规则。
Agent¶
大家可能会认为这个游戏里的Agent当然就只有一个,那就是吃豆人pacman。然而里面的敌人实际上也是agent,只不过pacman是我们关心的而已。
状态 State¶
状态是指对于agent而言,它对它所认知观察的环境进行建模。在这个游戏中,pacman可以观察到整个迷宫,知道所有的豆子、无敌豆在哪里,也知道敌人具体在哪里,同时还知道自己的具体位置。那么只需要状态State的表述能完整表示这些就ok了。
一种选择是用字典来表示:
| 坐标 | 标记 |
|---|---|
| (1,1) | 0 |
| (4,2) | 1 |
| (5,2) | 2 |
| (5,4) | 3 |
| (9,9) | 4 |
| ... | ... |
坐标很容易理解,它对应的就是我们游戏迷宫中的最小单元,也是pacman行走的最小单元;每个单元上只能有五种可能的状态,分别是0->什么都没有、1->普通豆子、2->无敌豆、3->敌人、4->pacman。
当然这只是一种选择,这种encoding需要人为编码,而现在的深度强化学习利用CNN直接从原始像素来对state进行表示。
动作 Action¶
Action是相对于Agent而言的,pacman的动作包括上、下、左、右。原地不动不是这个游戏中的选项,在任意时刻,pacman必须在这四个动作中选择一个。当然,遇到墙的时候,它看上去原地不动,本质上还是做出了动作。
奖励 Reward¶
强化学习的核心在于奖励的机制,没有奖励和惩罚,agent是不知道他做对了没有,或者做的多好。同时奖励的设定本身也定义了agent在环境中的目标。比如在pacman中,我们可以设定agent每走一步都得到-1的惩罚,这个是为了避免它自己转圈圈自嗨,也为了给它压力让它早点结束游戏;被其他的pacman吃掉,游戏就结束了,所以可以给一个更大的惩罚,比如-100;每吃一个豆子+1;每吃一个无敌豆+5;吃了无敌豆后每吃一个敌人+10。好了,这个可以作为我们对于这个游戏的奖惩设定。于是,最开始的那个强化学习概念图里的元素这里都有了。
交易游戏¶
实际上,交易本身也是一种游戏。下面来看我如何像pacman一样,把交易分解为强化学习的五个基本元素。
Environment¶
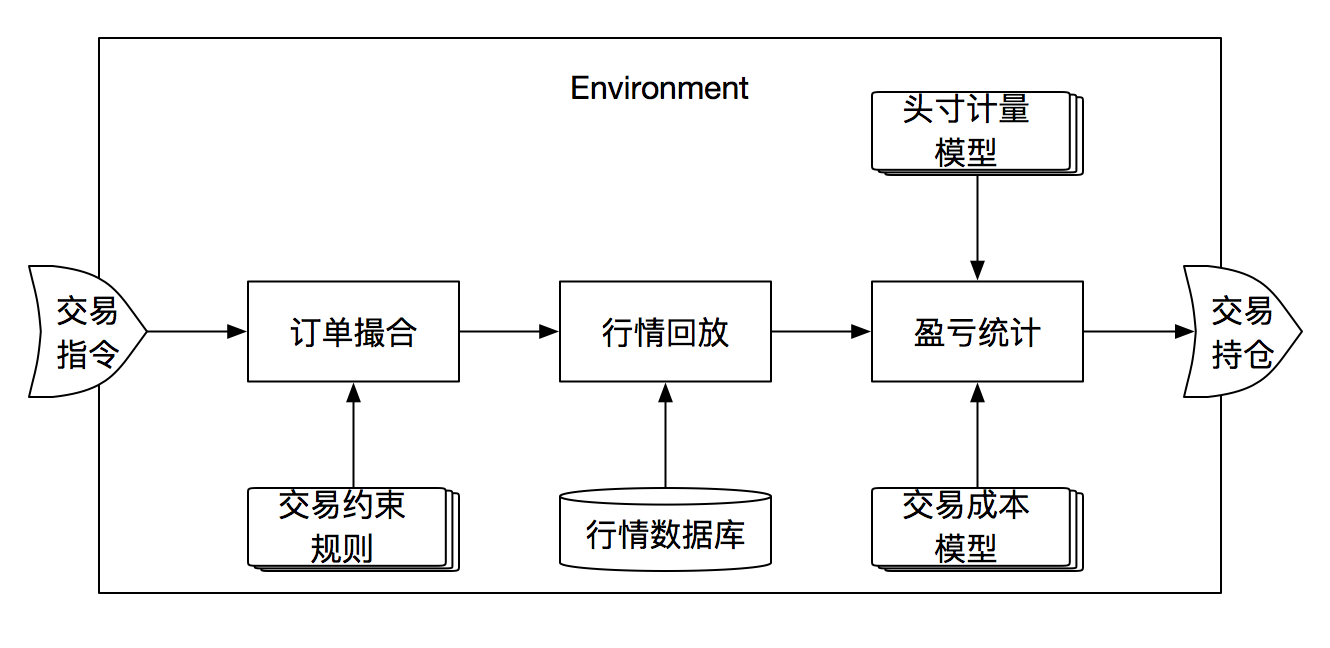
宏观意义上的环境就是我们的金融交易市场,里面有成千上万的交易对手、有做市商、有各种可交易的金融标的、以及各种经济、金融的资讯/信息。当然,在强化学习里,尤其是基于工程视角,这里的环境可以是一个交易回测引擎,也可以是在线交易平台。
如上图所示,交易回测引擎首先包含了一个订单撮合引擎,它用来模拟真实交易指令获得成交的过程,在这个过程中,可能包含的场景比如要拒绝无效交易订单,如涨跌停股票不能交易买入;还比如中国股市的T+1机制,T+0的订单不能被执行;还不如限价单、市价单的执行机制。然后就是行情回放或者行情模拟,这是核心的一部分,我们的资产标的价格以及相关信息会随着时间t不断更新,背后至少会有一个庞大复杂的行情数据库,可能是EOD、分钟行情、tick行情、order book等,可能还会包含衍生的指数数据、财务数据、宏观经济数据等。最后就是账户盈亏统计,其中包含对各种交易的计算汇总、头寸汇总、手续费计算、账户净值、账户现金等。
当然,对于agent,上述所有的规则并不一定要完全已知,agent不一定要知道交易成本的具体计算公式、交易限制如涨跌停/成交量限制。
State¶
State是agent对可观测环境的建模或者编码。首先很明显的就是agent需要知道当前的资产价格,很可能它还需要知道历史价格。不过大家要记住,不管是监督学习还是强化学习,都绝对不能包含仍和未来数据,在这里的state也是一样。也可以把一些技术指标、因子等加入state,有些人也会结合监督模型,把基于当前state(行情或因子)对股票价格或者其他特征的预测值编码为state的一部分。同时,state还比如包含至少当前的持仓信息,如每个资产的组合权重。
Action¶
交易agent的动作建模对接近实际场景的,就是每个时间t,给出一个所有资产的权重向量(包含现金)。根据这个权重向量,结合当前持仓(包含在当前的state里),就能知道当前还有哪些票需要换仓,换仓量是多少,于是变成了当前的交易指令传送给回测引擎或者environment。
Agent¶
我们的交易agent可以理解为就是我们的自动下单机器人,它每个时间只做三件事:分别是观察、决策和学习。 观察,就是在每个时间点能够从环境中获取到state信息,这几乎就是它能直接观察的全部信息了;决策就是在每个时间点决定agent要执行的action,比如建/换仓的股票列表以及权重,然后在agent执行action的同时,它能马上得到reward,这是我们agent与环境交互得到的另一个重要的信息。最后agent能够根据得到的信息,来学习、更新它的模型和参数。
Reward¶
Reward是能够让agent学习的核心,可以类比监督学习里的标注Label,监督学习里每一个example模型都能知道它做对了没有,label马上就能告诉它,然后通过损失函数让模型学习。在强化学习里,我们优化的是最终目标,比如游戏通关、交易财富净值最大等,但只有等到一个episode完成了过后,或者一次模型完成后,我们才能确定我们做的好不好,但是如果我们只在“游戏”结束时才对agent进行奖励和惩罚,很可能让agent学习得太慢,效果不佳,这就是强化学习里所谓的延迟奖励。但如果我们能在每一步都对agent进行奖惩,就更容易学习。在我们的交易游戏里,可以在每个时间点上用当时的交易损益来作为reward,也就是我们把交易浮赢/亏作为奖惩机制。这么做的原因,也是因为这样的reward的设计和最终的组合净值是在设计上是一致的,每一步step的汇总就是最终的组合净值(可以考虑资本时间成本)。还有一种设计是在reward里加入风险的因素,不过这种设计我没尝试过,研究它的论文也不多,没有证明这种reward一定具有优势。
强化学习原理¶
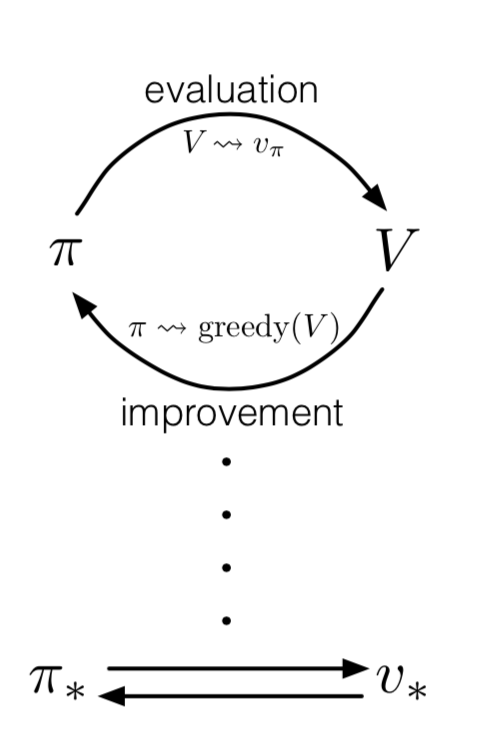
这不是一个旨在介绍强化学习的教程,所以在强化学习方面我们只介绍简单实用的概念及原理,但背后的理论复杂性和需要了解的远不止这些。强化学习原理大致我们从上图说起,强化学习最核心的包含两部分,那就是状态评估evaluation和策略改进improvement。
状态评估evaluation¶
我们之前介绍过,每一个agent都能观察到当前的状态state,但是状态有好有坏,比如在牛市我们更容易赚钱(当然,这取决与我们action的设计,如果我们action包含了做空的决策,那么对于交易agent来说,熊市和牛市可能具有一样的吸引力),我们需要一个机制来判断状态的好坏优劣。
于是,我们的第一个重要的公式出现了(我们尽可能在本教程不涉及复杂的数学):
$$v_{\pi}(s) = \mathbb{E}_{\pi} [G_t|S_t=s]$$$G_t$表示我们从时间t开始的未来累计reward或者说是未来所有reward在时间t的折现价值,与金融里的现值概念类似。但问题是这是一个“未来函数”,在时间t是不可观察的,那么我们就只能通过概率期望的方式来估计它。当然,我们更感兴趣的是在当前的情景下,我们的前景会怎么样?(比如,当前我已经有几只股票被重仓套牢,账户净值损失了50%,在我的交易技能不变的情况,一年后,我的账户净值能达到多少呢?)这正是状态评估在做的事情,它会对你的交易策略policy进行评估,比如在熊市阶段做多头会导致最终账户净值比较惨,那么它最终会学习到,已防止类似的state发生(在相同的市场状态下,空仓或者持有空头头寸就ok了,假设我们的state包含仓位状态的编码)。这里可能有一个概念大家容易搞混,我再啰嗦一下,在熊市的某个时间持有多头头寸和在那个时间下多头头寸是两个不同的概念,代表两个不同的state。前者在时间t已经持有了这个仓位了,仓位造成的损益已经发生了,不管你当下是了解仓位还是继续持有;后者在时间t并不持有仓位,这个时候你即使下多头头寸代表的也是你的行为,即action,不是state,所以这个时候你没有头寸,也就没有损益了,action只会对未来损益产生影响。
第二个重要的公式出现了:
$$q_{\pi}(s,a) = \mathbb{E}_{\pi} [G_t|S_t=s,A_t=a]$$上面的q我们称之为action-value函数、或者Q函数,我们常听到了Q-learning也是基于它。因为在实践中我们发现,往往评估Q函数会更加容易和方便,Q函数指的是,在某个状态下,agent执行某个行为的好坏评分。举个例子,当市场头肩顶的右肩已经形成,此时我持有多头仓位,如果我继续持有会怎么样?了结多头仓位呢?此时,Q函数能告诉你那个决策可能更好一些。Q函数和上面的V函数唯一的区别就是多了一个action的条件。
策略改进improvement¶
当我们得到了V函数或者Q函数,那么我们就可以得到我们最终的策略policy。那么,在强化学习里,policy到底是什么意思呢?RL一般这么定义policy:$\pi(a|s)$,即policy是在state条件概率下的action分布。还是举之前头肩顶的例子,假如我们的agent已经学习到了最优policy,它的policy告诉我在那个state下,继续持有的概率是30%,了解仓位的概率的70%。在我们假想的例子中,考虑到头肩顶本身并不可靠,所以最优策略也应该考虑到这种不确定性。如果在某个状态下不确定性非常小,$\pi(a|s)$也是有可能在那个状态下某个action收敛到接近1的概率。另外,很多时候,会让policy由概率分布收敛到值,比如在Q-learning中,我们会有一个argmax操作,另外policy的分布有时候也不是那么容易得到。有时候我们会满足在每个状态下获得最优的决策,即使最优决策与次优决策非常接近。
GPI¶
GPI本质上就是就是evaluation与improvement的迭代循坏,每一次迭代,都会让状态评估更准确、policy更接近最优策略,在收敛的情况下,V函数与policy会同时达到最优。当然,在实践中,evaluation与improvement可能会融合在一起。
结语¶
在这篇帖子里就先说那么多,感觉内容已经蛮多了,剩下的在下一篇里写吧。
参考文献¶
- Reinforcement Learning: An Introduction
- A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem